AI Second: Why Business Process Comes Before Artificial Intelligence
The AI-First Trap
It’s 2026, and AI is everywhere. Every vendor, consultant, and startup touts “AI-first” solutions:
- “AI-powered customer service” (chatbots replacing human support)
- “AI-driven analytics” (dashboards with ML models you don’t understand)
- “AI-enhanced workflows” (automation that breaks when data changes)
The promise is seductive: Deploy AI, solve problems instantly. But here’s what we’ve learned after nearly two decades of integrating AI and machine learning into enterprise systems:
AI-first often fails. Process-first with AI augmentation succeeds.
We call this “AI Second”—and it’s not about being anti-AI. It’s about being pro-results.
What is “AI Second”?
AI Second means:
- Understand the business process thoroughly (how does it work today? what are the pain points?)
- Design robust workflows that work reliably without AI (solid foundations)
- Identify specific opportunities where AI adds measurable value (narrow, well-defined problems)
- Integrate AI as an augmentation layer (humans + AI > either alone)
- Monitor and adapt continuously (AI models drift, processes evolve)
AI-First approach:
Problem → Deploy AI → Hope it works → Adjust later (maybe)
AI-Second approach:
Problem → Understand Process → Design Workflow → Identify AI Opportunity →
Integrate AI → Measure Results → Iterate
The second path requires more human thinking upfront—but leads to better, more reliable results.
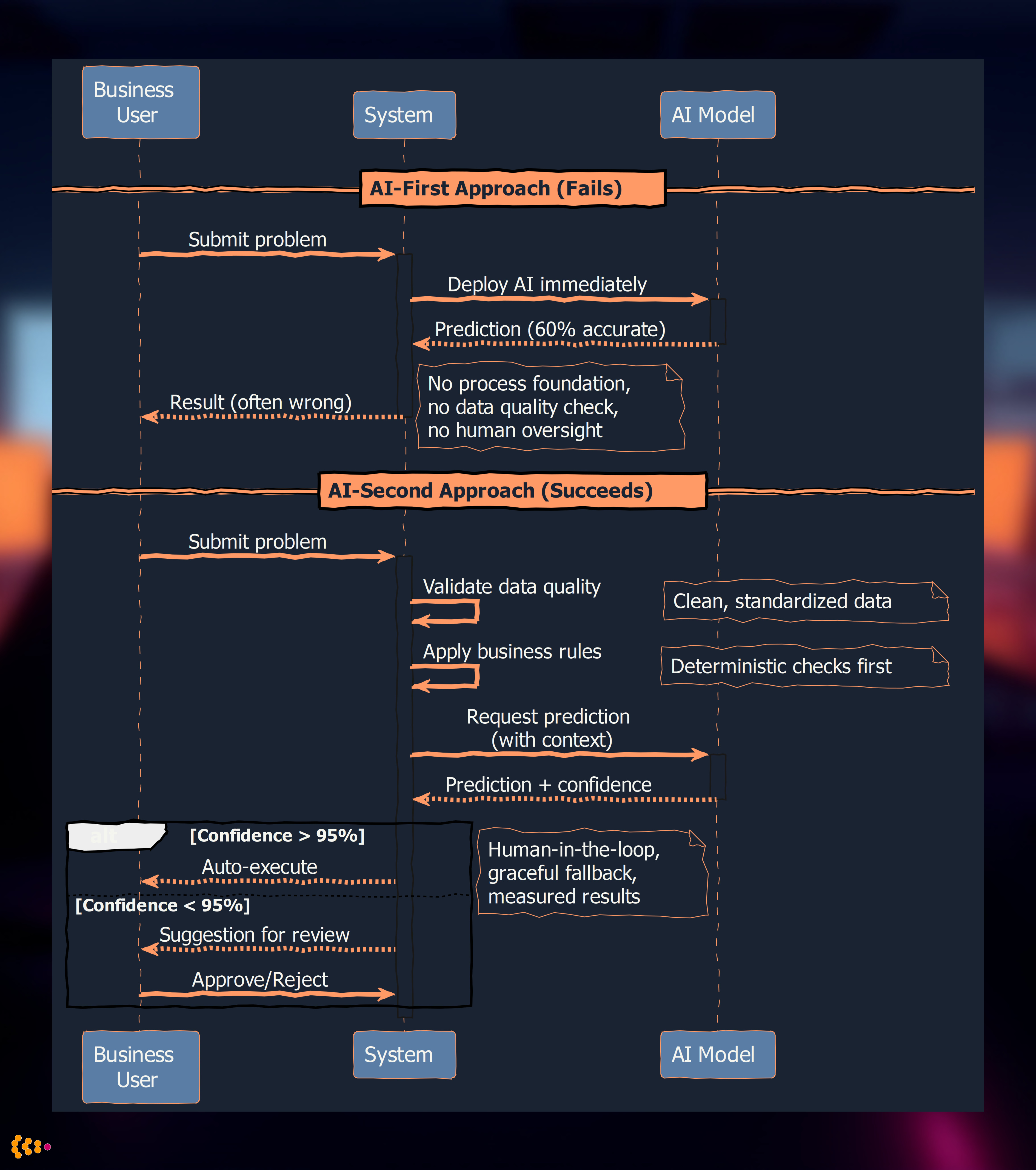
The sequence diagram above illustrates the critical difference: AI-First deploys AI without process foundation or data quality checks, while AI-Second validates data, applies business rules first, and uses confidence thresholds to determine when human review is needed.
Why AI-First Fails: Real-World Examples
Example 1: The “AI-Powered” Inventory System
Client: Manufacturing company promised an “AI-driven inventory optimization system” by a vendor.
Vendor Pitch:
- “Our ML model predicts demand with 95% accuracy!”
- “Reduce inventory costs by 30%!”
- “No manual forecasting needed!”
Reality After Deployment:
- Prediction accuracy: 95% on historical training data, but only 60% on new products (most of their catalog)
- Demand spikes: AI model failed to account for seasonal promotions (not in historical data)
- Result: Stockouts for popular items, excess inventory for slow movers—worse than manual forecasting
What Went Wrong:
- No process foundation: Company didn’t have clean data (duplicate SKUs, inconsistent categories)
- AI as magic: Vendor assumed ML could overcome data quality issues
- No human oversight: Model ran autonomously, no review of predictions before ordering
AI-Second Approach Would Have:
- Audit data quality first: Clean SKU database, standardize categories
- Build baseline process: Simple reorder point system with human review
- Identify AI opportunity: “Can ML improve demand forecast for mature products with 2+ years of history?”
- Pilot with guardrails: Run AI predictions alongside manual forecasts, humans review discrepancies
- Gradual rollout: Expand AI to more products as accuracy proves out
Example 2: Chatbot Customer Support Disaster
Client: E-commerce retailer deployed chatbot to “reduce support costs.”
Vendor Pitch:
- “Handle 80% of customer inquiries automatically!”
- “24/7 support without hiring more staff!”
Reality:
- 80% handled: True, but “handled” meant chatbot responded, not resolved
- Customer frustration: “I just want to talk to a human!” became the most common message
- Support tickets increased: Customers escalated to email/phone after chatbot failed, creating more work
What Went Wrong:
- No understanding of inquiry types: 80% of inquiries could be answered, but chatbot only succeeded on simple FAQs (20%)
- AI as replacement: Chatbot positioned as human replacement, not assistance
- No fallback process: When chatbot failed, no clear escalation path
AI-Second Approach Would Have:
- Categorize inquiries: Analyze 6 months of support tickets—what % are simple FAQs? Complex order issues? Complaints?
- Build knowledge base first: Comprehensive, searchable FAQ section (humans can use it too!)
- Identify AI opportunity: “Can chatbot handle simple FAQs (order status, shipping policy) while routing complex issues to humans?”
- Design hybrid workflow: Chatbot answers simple questions, immediately offers “talk to human” option, routes complex cases
- Measure success: Track resolution rate (not just response rate), customer satisfaction, time to resolution

The UI mockup above shows the AI-Second design in practice: the chatbot handles simple FAQs (“Where is my order?”) but immediately recognizes complex requests (“change delivery address”) and offers multiple human escalation paths with a single click.
Result with AI-Second: Chatbot handles 30% of simple inquiries (not 80% poorly), customer satisfaction improves, support staff focus on complex cases.
AI Second in Practice: Our Projects
1. Pharmaceutical Supply Chain: Blockchain First, AI Second (2018-2020)
Context: Pharmaceutical supply chain tracing with Hyperledger Fabric blockchain (detailed case study).
AI Opportunity Identified: Anomaly detection for suspicious shipment patterns (potential counterfeiting, diversion).
Why Not AI-First:
- Foundation needed: Reliable chain-of-custody data from blockchain
- Regulatory compliance: FDA requires deterministic traceability (blockchain provides this), AI predictions alone insufficient
AI-Second Approach:
- Build blockchain ledger: Immutable record of every shipment, custody transfer, verification
- Establish baseline: Define normal shipment patterns (typical routes, transit times, custody chains)
- Identify AI opportunity: “Can ML detect anomalies in shipment patterns that humans might miss?”
- Develop ML model: Train on 2 years of blockchain data—flag shipments with unusual patterns:
- Unexpected custody transfers (e.g., pharmaceutical shipped to non-pharmacy location)
- Transit time anomalies (unusually fast/slow for route)
- Suspicious verification patterns (batch verified in multiple locations simultaneously—impossible unless counterfeit)
Integration:
- Blockchain: Source of truth (human-auditable, regulatory-compliant)
- ML model: Generates alerts for compliance team to investigate
- Human decision: Compliance specialist reviews flagged shipments, decides if investigation needed
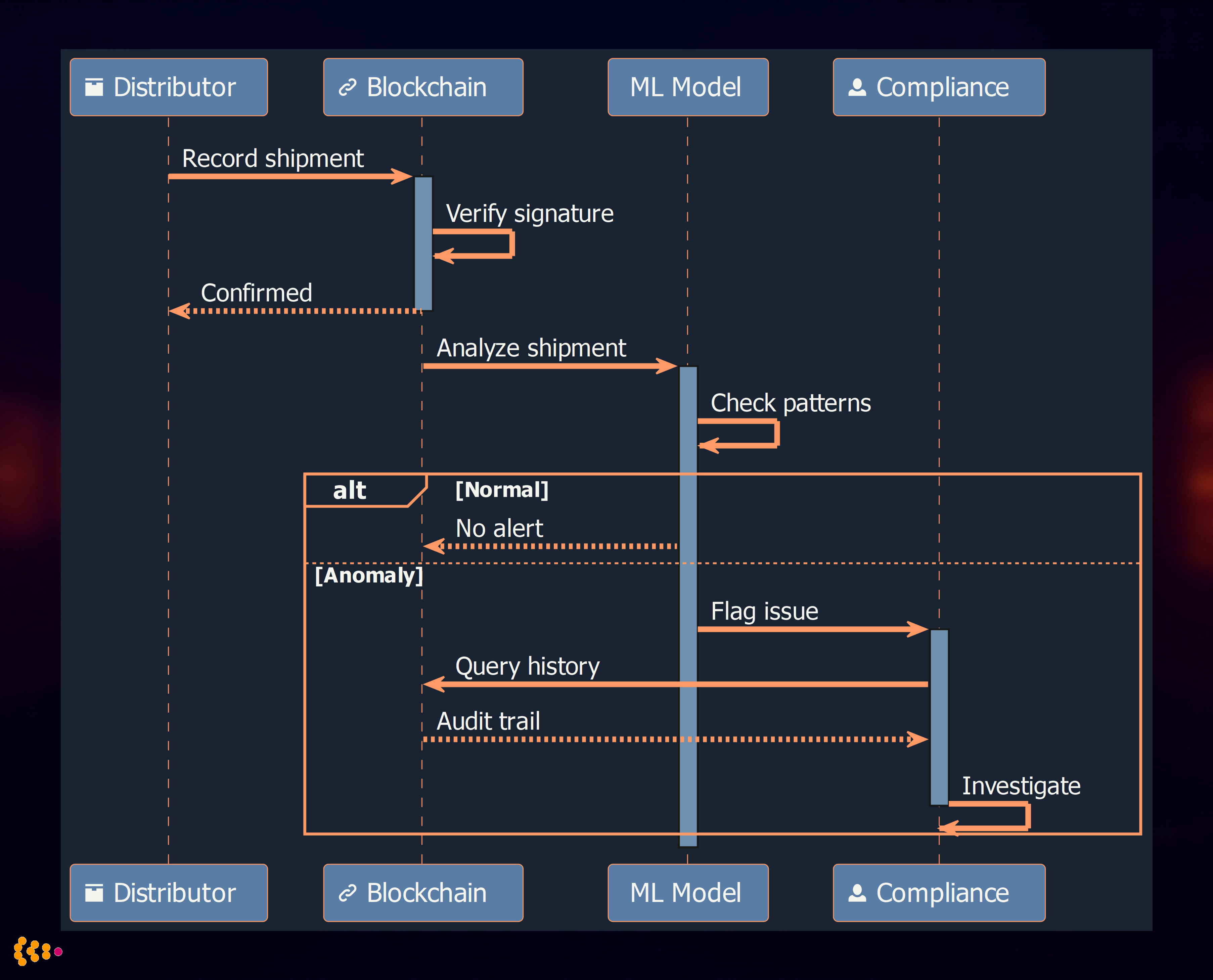
The sequence diagram illustrates the blockchain-first, AI-second architecture: every shipment is recorded immutably on the blockchain (deterministic traceability), while ML analyzes patterns to flag anomalies for human investigation.
Results:
- Compliance maintained: 100% blockchain traceability (regulatory requirement met)
- Early detection: ML flagged 3 counterfeit shipments before they reached pharmacies (caught in distribution)
- False positives managed: 15% false positive rate acceptable because humans review (low cost, high value)
Key Insight: AI augmented the process but didn’t replace deterministic blockchain traceability. If we’d done “AI-first,” we’d have ML predictions without auditable proof—unacceptable for pharma compliance.
2. Automotive CAD-PDM Integration: Rules Engine First, AI Second (2010-2015)
Context: Automotive OEM CAD to PDM to SAP integration (detailed in SAP integration post).
Challenge: Validating engineering BOMs (Bills of Materials) before release to manufacturing.
Validation Rules (examples):
- Material compatibility: Aluminum part can’t be welded to titanium (different melting points)
- Mass constraints: Suspension assembly must be <50kg
- Regulatory: Brake components must use certified materials (DOT-approved)
Why Not AI-First:
- Safety-critical: Automotive engineering errors can cause injuries/deaths—no “95% accurate” acceptable
- Regulatory compliance: Engineering validation must be auditable and deterministic
Process-First Approach:
- Define validation rules: Work with engineering team to codify 200+ validation rules
- Implement rules engine: Drools (Java-based rules engine) executes deterministic checks
- Human review: Engineering team reviews validation failures, corrects issues before release
AI-Second Integration (Added 2013):
- Opportunity identified: “Can ML suggest likely material substitutions when validation fails?”
- Example: BOM uses discontinued material X → ML suggests similar material Y based on historical substitutions
- ML model: Trained on 5 years of engineering changes—when material substituted, what was chosen?
- Integration: When rules engine flags discontinued material, ML model suggests alternatives (engineer makes final decision)
Results:
- Safety maintained: Deterministic rules catch all violations (100% enforcement)
- Efficiency gained: ML suggestions reduced time to resolve validation failures by 40% (engineers don’t manually search for substitutes)
- Trust built: Engineers trust suggestions because they understand the rules—AI is helper, not black box
3. Publishing: Metadata Enrichment with AI (Since 2017)
Context: Publishers need rich metadata for books (keywords, categories, genre tags) for SEO, Amazon optimization (publishing industry post).
Manual Process (before AI):
- Author/editor assigns keywords, categories manually
- Time-consuming: 15-30 minutes per book
- Inconsistent: Different editors use different terminology
AI-Second Approach:
- Build metadata schema first: Define standard categories, controlled vocabulary (taxonomy)
- Human baseline: Train editors on metadata standards, create 6 months of high-quality examples
- Identify AI opportunity: “Can NLP suggest keywords and categories based on manuscript text?”
- Develop NLP model: Train on 1,000 books with manually-assigned metadata
- Extract keywords from title, description, manuscript sample
- Predict BISAC categories (industry-standard book categories)
- Integration:
- AI suggests keywords and categories when book created in CMS
- Editor reviews and approves suggestions (can accept, reject, or modify)
Results:
- Time savings: Metadata assignment reduced from 20 minutes to 5 minutes per book
- Quality improvement: AI suggestions prompt editors to consider keywords they might have missed
- Consistency: Controlled vocabulary enforced (AI trained on standard taxonomy)
Key Insight: AI didn’t replace editorial judgment—it accelerated it. Editors retained control, ensuring metadata quality while saving time.
The AI Second Principles
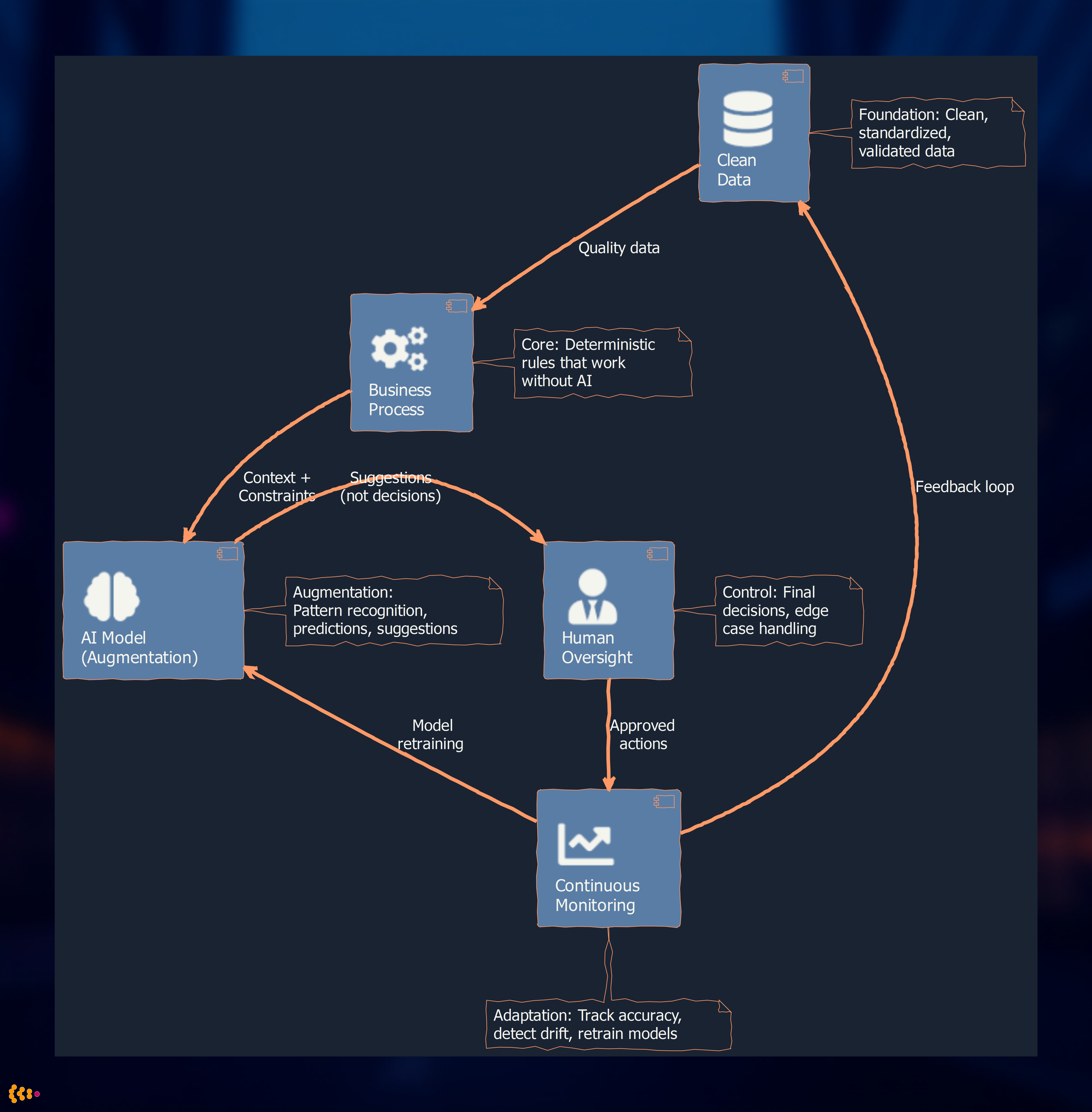
The architecture diagram above shows the five pillars of AI-Second design: clean data feeds robust business processes, which provide context to AI models. AI generates suggestions (not decisions) for human oversight, while continuous monitoring creates feedback loops for model improvement.
1. Humans Define Success, AI Optimizes
Don’t ask AI: “What should we do?”
Ask AI: “Given this goal (we’ve defined), how can you help us achieve it better?”
Example: Inventory optimization
- Wrong: “AI, optimize our inventory” (what does “optimize” mean? Cost? Availability? Both? Trade-offs?)
- Right: “We want 95% product availability with minimum inventory cost. AI, predict demand so we can order smarter.”
Humans define the objective function (95% availability, minimize cost). AI optimizes within those constraints.
2. Transparency Beats Accuracy (Sometimes)
A simple, explainable model you trust beats a complex, accurate model you don’t understand.
Example: Credit risk scoring
- Black box deep learning: 92% accuracy, but no explanation why loan denied (regulatory problem, customer frustration)
- Logistic regression: 89% accuracy, clear feature weights (e.g., debt-to-income ratio > 40% = high risk)
For many business applications, the 3% accuracy gain isn’t worth the loss of interpretability.
Our approach: Start with interpretable models (decision trees, linear regression, rules). Use complex models (neural nets, ensembles) only when interpretability isn’t critical and accuracy gain is substantial.
3. AI Should Fail Gracefully
When AI predictions are wrong (and they will be), the system must degrade gracefully, not catastrophically.
Design patterns:
- Human-in-the-loop: AI suggests, human approves (pharmaceutical anomaly detection)
- Confidence thresholds: Only auto-execute when AI is >95% confident, otherwise flag for review
- Fallback to rules: If ML model fails (e.g., new product with no historical data), fall back to deterministic rules
Anti-pattern: Fully autonomous AI with no oversight (the chatbot disaster example).
4. Data Quality > Model Complexity
80% of AI success is clean, relevant data. 20% is model tuning.
Reality check:
- Spending 3 months tuning a neural network on dirty data: Wasted effort
- Spending 3 months cleaning data, then training simple model: High ROI
Our process:
- Audit data quality: Completeness, accuracy, consistency
- Clean and standardize: Fix duplicates, missing values, inconsistent formats
- Start simple: Train baseline model (linear regression, decision tree)
- Iterate: If baseline isn’t good enough, try complex models—but only after data is clean
5. Monitor and Adapt Continuously
AI models drift: What works today may not work in 6 months (customer behavior changes, product mix shifts, market conditions evolve).
Our practice:
- A/B testing: Run new model alongside old, compare results before full rollout
- Performance dashboards: Track model accuracy, prediction distribution, error rates
- Retraining schedules: Retrain models quarterly (or more frequently if drift detected)
- Human feedback loops: Let users flag bad predictions, use feedback to improve model
Our AI Journey: 2007 to 2024
Early Days (Late 2000s): Machine Learning for Analytics
- Regression models: Predicting automotive part failure rates based on material properties, usage patterns
- Clustering: Segmenting customers for marketing campaigns (publishing industry)
- Tools: R, WEKA, basic Python (scikit-learn early versions)
Philosophy Even Then: Use ML to augment human analysis, not replace it. Analysts reviewed model outputs, made final decisions.
Growth (2013-2018): NLP and Recommendation Systems
- Text classification: Categorizing engineering documents, support tickets
- Recommendation engines: “Customers who bought X also bought Y” for e-commerce clients
- Tools: Python (NLTK, spaCy), TensorFlow (early days)
Learning: NLP is powerful but brittle—slight wording changes can break models. Combine NLP with rule-based fallbacks.
Modern Era (2019-Present): Deep Learning and LLMs
- Neural networks: Image recognition (quality inspection in manufacturing), time series forecasting
- Large language models: LLM-MCP integration for CAD metadata (detailed post)
- Tools: PyTorch, Hugging Face Transformers, OpenAI API, Claude API
Current Focus: Responsible AI—ensuring LLMs provide accurate, auditable, permission-aware responses (LLM-MCP project is exemplar).
Our Research Blog: Notes on Personal Data Science
For nearly two decades, we’ve followed AI/ML research closely and documented our explorations at:
Notes on Personal Data Science
Topics we’ve covered:
- Reinforcement learning: Training game-playing agents (Bitcoin RL project for OUYA)
- Neural network fundamentals: “Why Neural Networks Work” (exploring gradient descent, backpropagation)
- Practical ML: Applied techniques for small/medium datasets (most businesses don’t have Google-scale data)
- AI ethics: Bias in ML models, fairness considerations
Philosophy: Share lessons learned, demystify AI, focus on practical applications over academic novelty.
When to Use AI vs. When to Use Deterministic Systems
Use Deterministic Systems (Rules, Algorithms) When:
- Safety-critical: Automotive braking systems, pharmaceutical compliance, financial trading (errors = lives/lawsuits)
- Regulatory requirements: Must explain every decision (credit scoring, insurance underwriting in some jurisdictions)
- Predictable domain: Problem has well-defined rules (tax calculations, engineering validation constraints)
- Small data: Insufficient data to train reliable ML model (<1,000 examples)
Examples: Blockchain traceability, engineering BOM validation, financial reporting, legal compliance checks.
Use AI/ML When:
- Pattern recognition in large data: Detecting fraud, predicting demand, image/speech recognition
- Personalization: Recommendation engines, dynamic pricing, content customization
- Complex, high-dimensional problems: Too many variables for humans to track (supply chain optimization with 1,000s of SKUs)
- Adaptability needed: Domain changes over time, rules are too rigid (customer preferences evolve, market dynamics shift)
Examples: Demand forecasting, NLP for metadata extraction, anomaly detection, image quality inspection.
Use Hybrid (AI + Deterministic) When:
- Best of both worlds: Rules for known cases, AI for edge cases or suggestions
- High stakes with flexibility needs: Deterministic core with AI-assisted decision support
Examples: Automotive engineering (rules validate, AI suggests alternatives), pharmaceutical tracing (blockchain truth, AI flags anomalies), publishing metadata (taxonomy rules, AI suggests keywords).
Why “AI Second” Requires More Human Thinking (And Why That’s Good)
AI-First is seductive because it promises to skip the hard work:
- “Just deploy AI, it’ll figure it out!”
- “No need to understand the process, AI will optimize it!”
AI-Second demands:
- Deep process understanding: How does this work today? Where are bottlenecks?
- Clear problem definition: What are we trying to achieve? How do we measure success?
- Data quality work: Cleaning, standardizing, validating data (unglamorous but essential)
- Integration thinking: How does AI fit into existing workflows? What happens when it fails?
The Gantt chart above shows a typical AI-Second implementation timeline: 3 months for data quality and process foundation, 2 months for AI development, and 1 month for piloting and rollout—with continuous monitoring thereafter. This investment in foundation work is what makes AI integration sustainable.
This is harder—but leads to:
- Reliable systems: Failures are contained, not catastrophic
- Trust: Users understand what AI does (and doesn’t do)
- Sustainable value: Systems that work long-term, not just impressive demos
The Future: AI Is Underutilized, But Not Because We Need More AI
Paradox: Companies underutilize AI today—but the solution isn’t “add more AI.”
The real blockers:
- Dirty data: Can’t train good models on inconsistent, incomplete data
- Unclear objectives: “Use AI” isn’t a goal; “reduce customer churn by 10%” is
- Process chaos: AI can’t fix broken processes—it amplifies them (garbage in, garbage out)
- Lack of trust: Black box models scare business users (rightly so)
AI Second solves these:
- Process-first = clean data, clear objectives, reliable workflows
- AI as augmentation = trust through transparency, human oversight, gradual adoption
Result: More AI usage—but integrated thoughtfully, not sprinkled everywhere.
Conclusion: AI Second Delivers AI Success
We’ve been integrating AI and machine learning into enterprise systems for nearly two decades. We’ve seen AI-first projects fail spectacularly and AI-second projects deliver transformative value.
AI Second isn’t anti-AI—it’s pro-results:
- Build robust business processes first
- Integrate AI where it makes sense (narrow, well-defined problems)
- Design for human + AI collaboration (not AI replacement)
- Monitor, measure, adapt continuously
This requires more human thinking upfront—but delivers better, more reliable results.
If you’re exploring AI for your organization, ask:
- Do we understand our business process? (if not, fix that first)
- What specific problem would AI solve? (vague goals = vague results)
- How will we measure success? (beyond “we’re using AI”)
- What happens when AI is wrong? (it will be—design for graceful failure)
Answer these questions honestly, and you’re ready for AI Second—which paradoxically, is the path to AI success.
Blog: Notes on Personal Data Science (our AI/ML research blog)
Related Posts:
- LLM-MCP Integration (AI Second in practice: permission-aware, context-rich LLM integration)
- Pharmaceutical Blockchain (Blockchain for deterministic traceability, AI for anomaly detection)
About: HSEC has been integrating AI and machine learning into enterprise systems for nearly two decades, with a focus on practical, business-driven implementations that prioritize reliability over novelty.
Contact: Exploring AI integration for your organization? Let’s discuss an AI-Second approach.