Machine Learning and Neural Networks for Enterprise Applications
Beyond the Hype: ML That Works in Production
Machine learning and neural networks have moved from research labs to production enterprise systems. But the path from “90% accuracy in the lab” to “reliable business value in production” is filled with challenges that don’t appear in academic papers or vendor demos.
For nearly two decades, we’ve been integrating ML into enterprise systems where reliability matters more than novelty. Here’s what we’ve learned about making neural networks work in real business contexts.
The Enterprise ML Reality Check
What Enterprises Actually Need
Enterprise ML is different from consumer AI:
Reliability Over Accuracy
- A 95% accurate system that fails predictably is better than a 98% accurate system that fails randomly
- Confidence scores and uncertainty quantification are as important as predictions
- Fallback mechanisms when ML confidence is low
Explainability Matters
- “The model says so” doesn’t fly in regulated industries
- SHAP values, LIME, and attention visualization help explain decisions
- Compliance teams need audit trails showing why a prediction was made
Integration Complexity
- ML models don’t run in isolation—they’re part of larger enterprise workflows
- Data pipelines must handle missing data, outliers, and schema evolution
- Model versioning and A/B testing infrastructure are mandatory
Neural Networks in Practice: Our Projects
1. Predictive Maintenance for Manufacturing Equipment
Challenge: Automotive manufacturing plant wanted to predict equipment failures before they caused production line downtime.
The ML Architecture:
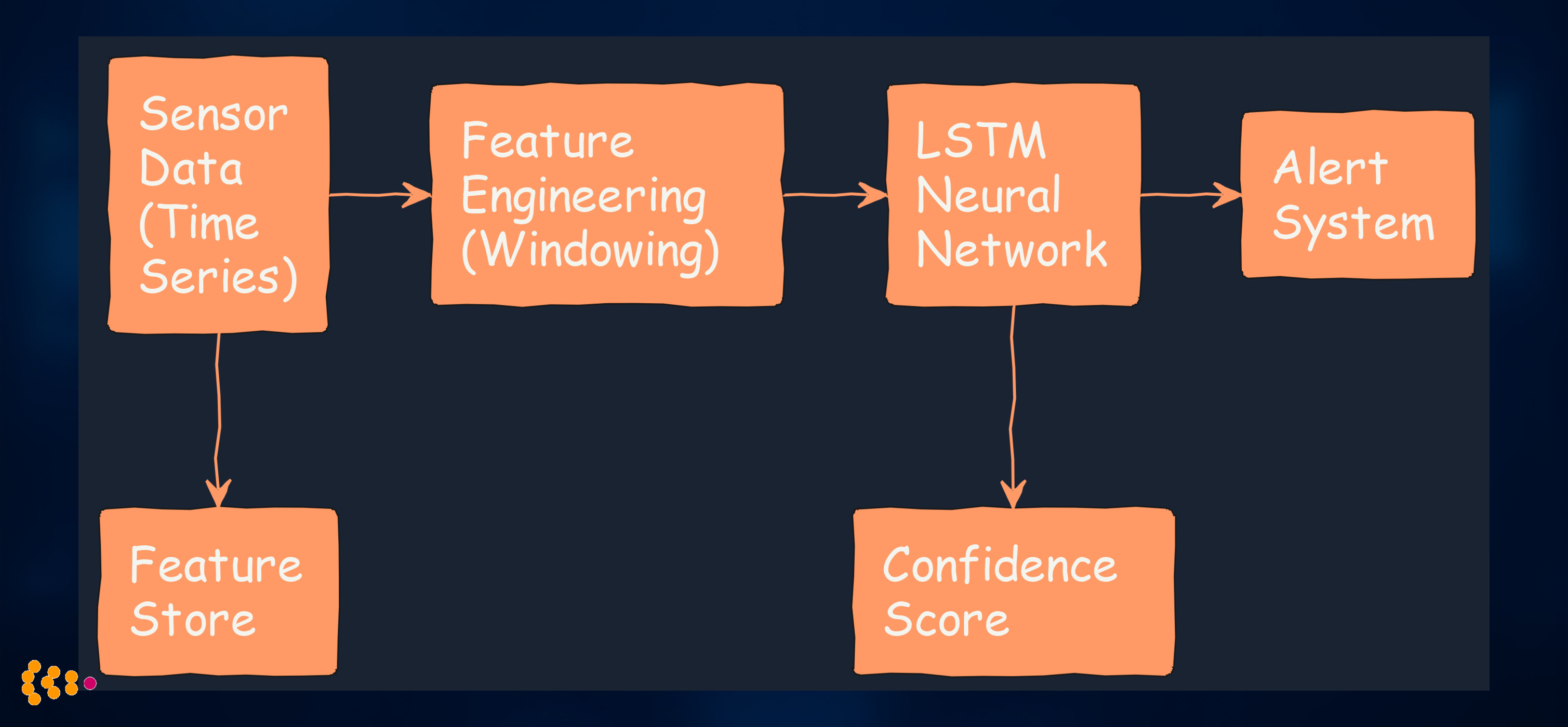
Technical Approach:
- LSTM (Long Short-Term Memory) networks for time-series sensor data
- Feature engineering: Vibration frequency bands, temperature gradients, operational cycles
- Multi-task learning: Predict both failure probability and time to failure
- Confidence thresholds: Only alert when model confidence > 85%
Implementation Details:
# Simplified LSTM architecture for predictive maintenance
import torch
import torch.nn as nn
class MaintenanceLSTM(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers):
super().__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
self.failure_prob = nn.Linear(hidden_dim, 1)
self.time_to_failure = nn.Linear(hidden_dim, 1)
def forward(self, x):
lstm_out, _ = self.lstm(x)
last_hidden = lstm_out[:, -1, :]
failure_prob = torch.sigmoid(self.failure_prob(last_hidden))
ttf = torch.relu(self.time_to_failure(last_hidden))
return failure_prob, ttf
Results:
- 78% reduction in unplanned downtime
- 45% lower maintenance costs (scheduled vs. emergency repairs)
- False positive rate < 12% (acceptable for maintenance scheduling)
- Confidence scoring allowed operators to prioritize alerts
Lessons Learned:
- Domain expertise matters: Mechanical engineers’ input on feature engineering was critical
- Start simple: Initial linear models established baseline before neural networks
- Monitor data drift: Sensor degradation changed input distributions over time
2. Demand Forecasting with Transformers
Challenge: Publisher needed accurate sales forecasts for print-on-demand inventory planning across 20+ international markets.
The ML Stack:
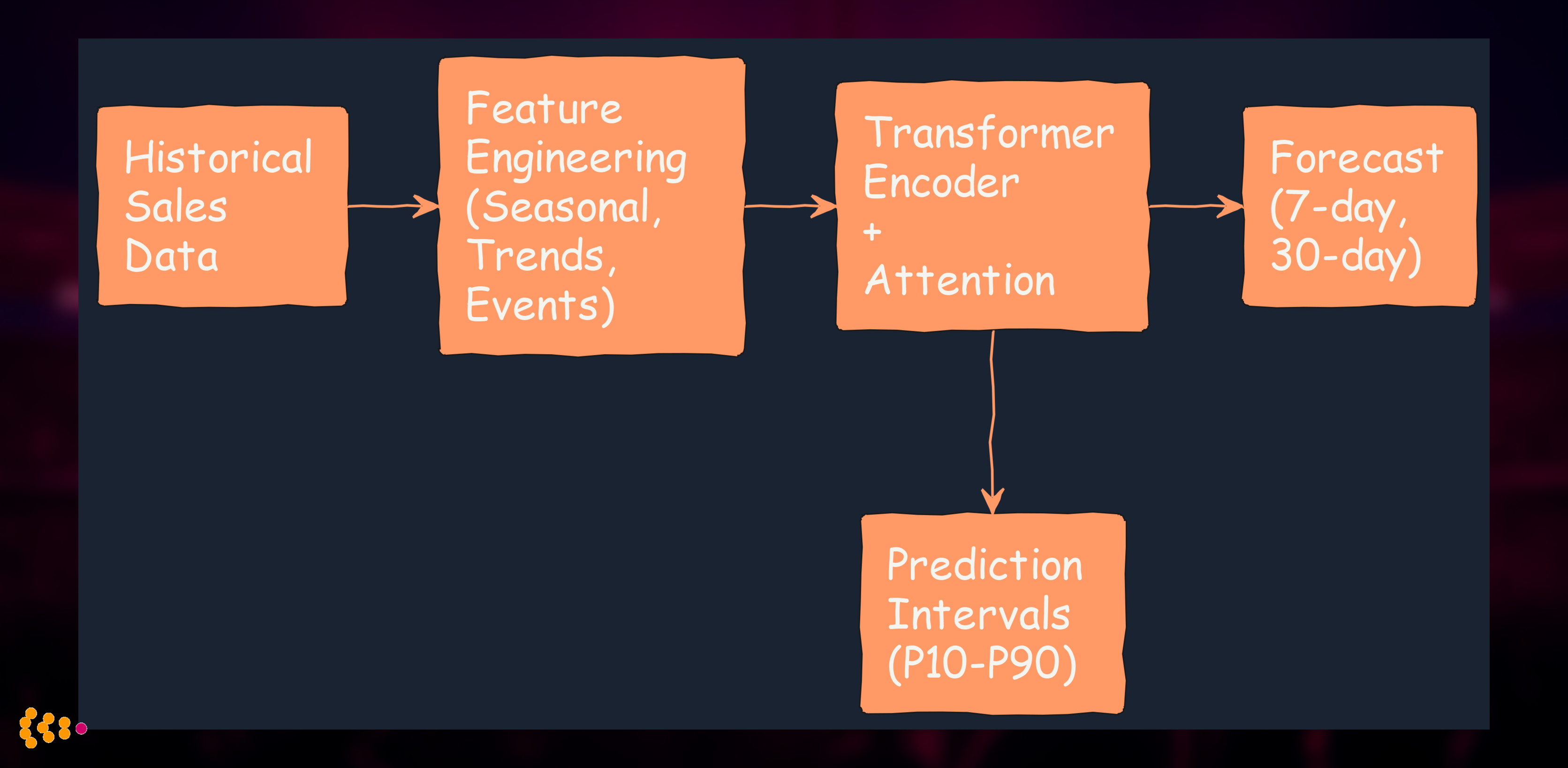
Technical Approach:
- Temporal Fusion Transformer architecture (modified from Google’s TFT)
- Multi-horizon forecasting: 7-day and 30-day predictions simultaneously
- Quantile regression: P10, P50, P90 predictions for inventory optimization
- External features: Marketing campaigns, seasonality, holidays, book launches
Why Transformers Over LSTMs?:
- Attention mechanism captures long-range dependencies (e.g., previous year’s holiday sales)
- Interpretable attention weights show which historical periods influenced each forecast
- Better handling of irregular events (book launches, media appearances)
Results:
- 23% improvement in forecast accuracy vs. traditional time-series methods
- 18% reduction in excess inventory
- Prediction intervals enabled risk-based inventory decisions
- Attention visualization helped marketing team understand sales drivers
3. NLP for Metadata Enrichment in CAD Systems
Challenge: Engineers struggled to find CAD parts because metadata was inconsistent, incomplete, or outdated.
The NLP Pipeline:
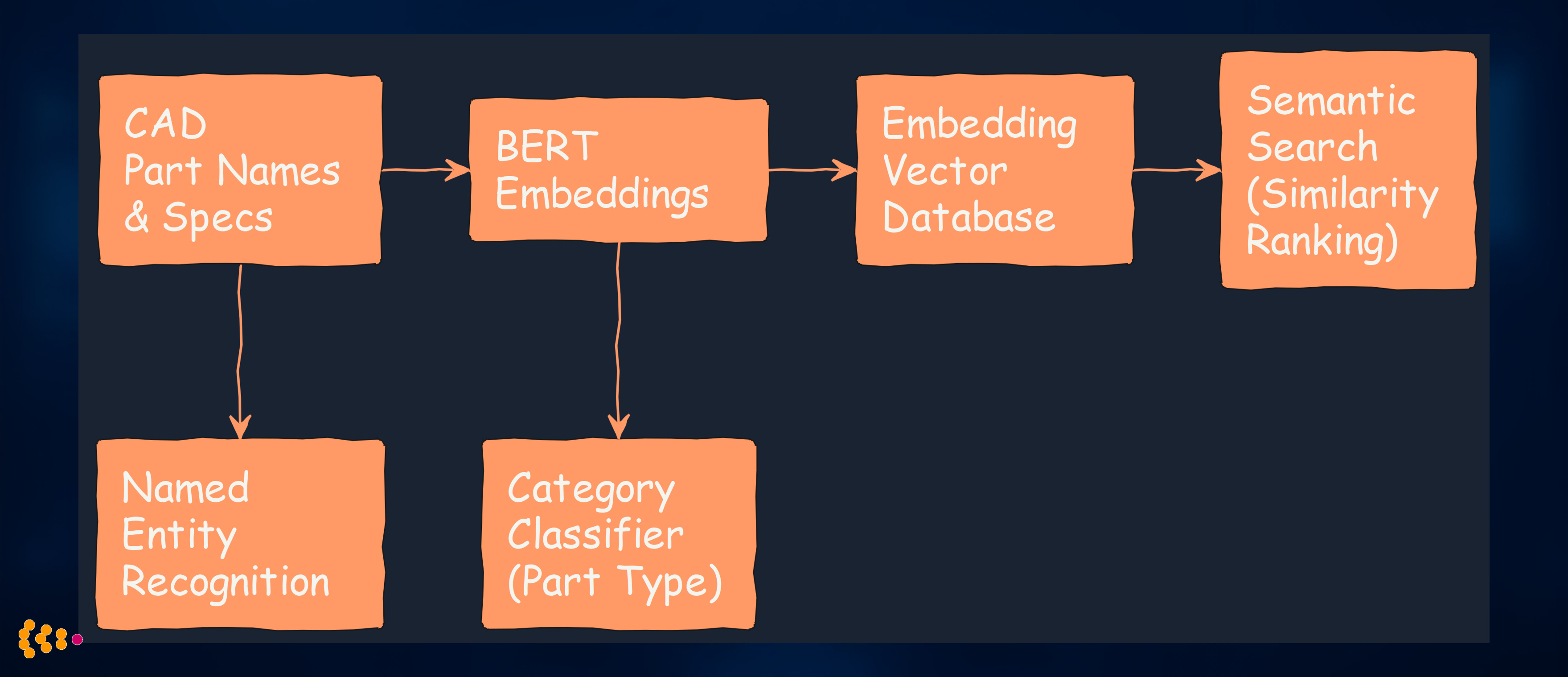
Technical Stack:
- BERT embeddings (fine-tuned on automotive engineering vocabulary)
- Named Entity Recognition: Extract material specs, dimensions, tolerances
- Zero-shot classification: Categorize new parts without manual labeling
- Vector similarity search: Find semantically similar parts (not just keyword matching)
Implementation:
from transformers import BertTokenizer, BertModel
import torch
class PartMetadataEnricher:
def __init__(self, model_name="bert-base-uncased"):
self.tokenizer = BertTokenizer.from_pretrained(model_name)
self.model = BertModel.from_pretrained(model_name)
def enrich_metadata(self, part_description):
# Generate embeddings
inputs = self.tokenizer(part_description, return_tensors="pt")
outputs = self.model(**inputs)
embeddings = outputs.last_hidden_state[:, 0, :] # CLS token
# Find similar parts via vector search
similar_parts = self.vector_db.search(embeddings, top_k=10)
# Extract entities (materials, dimensions)
entities = self.ner_model.predict(part_description)
return {
"embeddings": embeddings,
"similar_parts": similar_parts,
"extracted_entities": entities
}
Results:
- 60% reduction in CAD search time
- Semantic search understands synonyms (“aluminum” = “aluminium”) and related concepts
- Automatic categorization of 50,000+ legacy parts
- Multilingual support (German/English engineering terminology)
4. Anomaly Detection in Supply Chain Networks
Challenge: Pharmaceutical supply chain needed to detect counterfeit products, routing anomalies, and unusual transaction patterns.
The Anomaly Detection System:
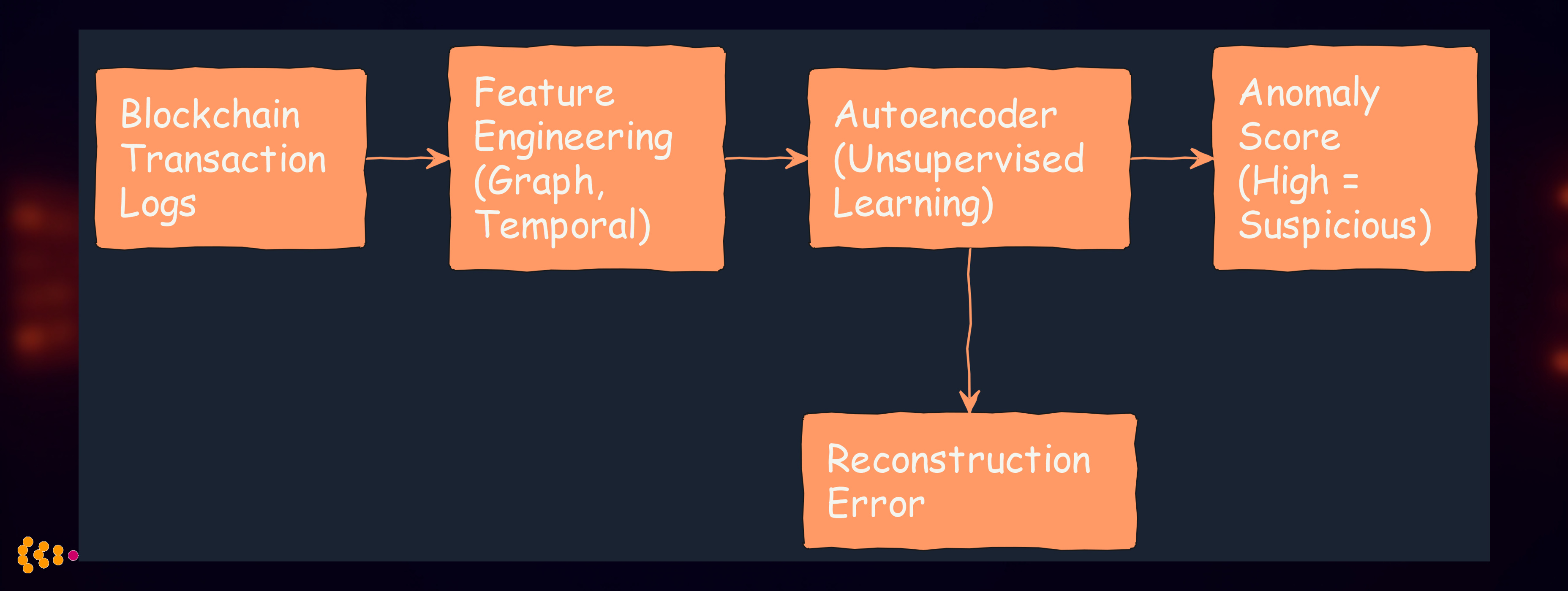
Technical Approach:
- Variational Autoencoder (VAE) trained on normal transaction patterns
- Graph Neural Network to model supply chain relationships
- Reconstruction error identifies unusual patterns
- Ensemble methods: Combine VAE + Isolation Forest + statistical outlier detection
Key Insight:
- Unsupervised learning works because we have lots of normal data, few anomalies
- False positives are acceptable: Flagged transactions get manual review
- Explainability: Show which features contributed to anomaly score
Results:
- 3 counterfeit shipments detected in first 6 months
- 92% detection rate in simulated attack scenarios
- Low false positive rate (< 5% of transactions flagged)
- Integration with Hyperledger Fabric blockchain for tamper-proof audit trail
Neural Network Engineering Best Practices
1. Start Simple, Add Complexity Gradually
Anti-pattern: Jump straight to transformers or deep RL
Better approach:
- Linear baseline: Logistic regression, linear regression
- Tree-based methods: XGBoost, Random Forest (often surprisingly competitive)
- Simple neural networks: Feedforward, single LSTM layer
- Complex architectures: Only if simpler methods fail
2. Data Quality > Model Complexity
The 80/20 Rule: Spend 80% of effort on data, 20% on models
Data Engineering Priorities:
- Feature engineering based on domain knowledge
- Data cleaning: Handle missing values, outliers, duplicates
- Train/test split that reflects production conditions
- Data versioning (DVC, MLflow) for reproducibility
3. Monitor Everything in Production
ML Systems Degrade Over Time:
What to Monitor:
- Prediction distribution drift: Are predictions changing over time?
- Feature distribution drift: Are inputs different from training data?
- Model confidence: Is the model less confident than before?
- Business metrics: Is the model still delivering value?
Automated Retraining:
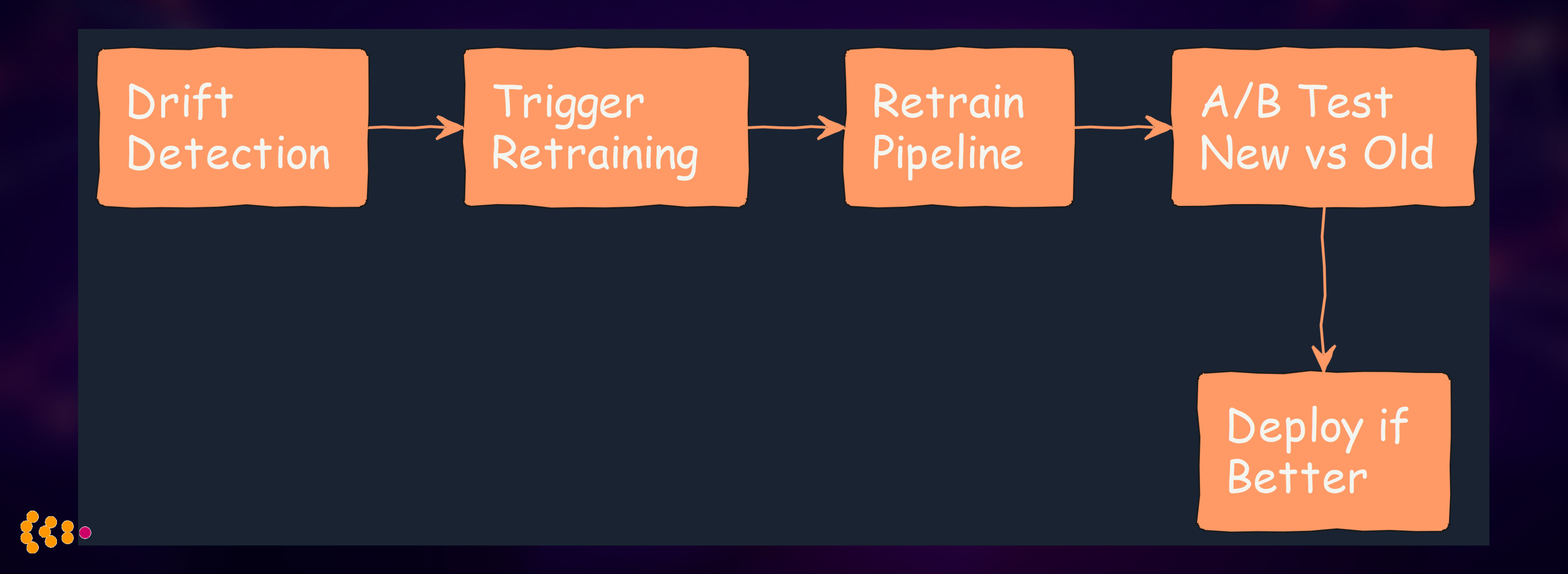
4. Explainability is Non-Negotiable
Techniques We Use:
- SHAP (SHapley Additive exPlanations): Feature importance for individual predictions
- LIME (Local Interpretable Model-agnostic Explanations): Local approximations
- Attention visualization: For transformers and attention-based models
- Counterfactual explanations: “If feature X changed by Y, prediction would be Z”
Technology Stack for Enterprise ML
Deep Learning Frameworks
PyTorch (our primary choice):
- Flexible, Pythonic API
- Great for research and production
- Strong ecosystem (Hugging Face, PyTorch Lightning)
TensorFlow/Keras:
- Better for deployment (TensorFlow Serving)
- Wider support for edge devices
ML Operations (MLOps)
Experiment Tracking:
- MLflow: Track experiments, models, parameters
- Weights & Biases: Experiment visualization, collaboration
Model Serving:
- TorchServe: PyTorch models in production
- TensorFlow Serving: TensorFlow models
- FastAPI + Docker: Custom serving for flexibility
Feature Stores:
- Feast: Open-source feature store
- Tecton: Managed feature platform (for larger deployments)
Infrastructure
Training:
- On-premise GPUs: NVIDIA A100, V100 for sensitive data
- Cloud GPU instances: AWS EC2 P4, Google Cloud TPUs for scalability
Production:
- Kubernetes: Model serving, autoscaling
- Docker: Containerization for reproducibility
Common Pitfalls (and How to Avoid Them)
Pitfall 1: Overfitting to Benchmarks
Problem: Model performs great on test set, fails in production
Solution:
- Hold-out set from production: Save recent data for final validation
- Temporal validation: Train on older data, test on newer data
- Cross-validation with production-realistic splits
Pitfall 2: Ignoring Operational Costs
Problem: Model requires GPU inference, budget only allows CPU
Solution:
- Model compression: Quantization, pruning, distillation
- Simpler architectures: Sometimes a smaller model is better
- Batch prediction: Amortize GPU costs over many predictions
Pitfall 3: No Plan for Model Updates
Problem: Model degrades, no process to retrain/redeploy
Solution:
- Automated retraining pipelines (weekly, monthly)
- A/B testing infrastructure for safe rollouts
- Rollback capability when new models underperform
The Future: Where We’re Heading
Trends We’re Watching
1. Foundation Models for Industrial AI
- Pre-trained models fine-tuned for manufacturing, supply chain
- Transfer learning reduces data requirements
- Our experiments: Fine-tuning GPT for part descriptions, technical documentation
2. Federated Learning for Sensitive Data
- Train models across multiple sites without sharing data
- Critical for healthcare, automotive suppliers
- Our pilot: Federated anomaly detection across pharmaceutical distributors
3. Hybrid AI: Neural Networks + Symbolic Reasoning
- Combine deep learning with business rules
- Neural networks for pattern recognition, rules for compliance
- Our approach: “AI Second” philosophy applied to neural networks
4. Edge AI: Models on Industrial Devices
- Deploy neural networks on edge devices (manufacturing equipment, IoT sensors)
- Reduce latency, improve privacy
- Our research: TinyML for predictive maintenance on PLCs
Lessons Learned: Neural Networks in Enterprise
What Works
✅ Domain expertise + ML engineering: Best results come from collaboration
✅ Simple baselines first: Establish what “good enough” looks like
✅ Gradual complexity: Add neural networks only when simpler methods fail
✅ Production monitoring: ML systems require ongoing care
✅ Explainability: Critical for trust and compliance
What Doesn’t Work
❌ “AI will solve everything”: Neural networks are tools, not magic
❌ Ignoring data quality: Garbage in, garbage out
❌ One-time training: Models degrade without retraining
❌ Black boxes: Unexplainable models fail in regulated industries
❌ Vendor lock-in: Build with open-source, deploy flexibly
Conclusion
Machine learning and neural networks are powerful tools for enterprise applications—when applied thoughtfully. The key is treating ML as engineering, not magic:
- Start with business problems, not cool algorithms
- Build robust data pipelines before complex models
- Monitor, retrain, and improve continuously
- Explain predictions to earn stakeholder trust
- Integrate with existing systems for real business impact
After nearly two decades of ML integration, we’ve learned that the best enterprise AI is reliable, explainable, and integrated—not necessarily the most cutting-edge.
Technologies Used: Python, PyTorch, TensorFlow, Hugging Face Transformers, scikit-learn, XGBoost, MLflow, FastAPI, Docker, Kubernetes, BERT, LSTM, Transformers, Variational Autoencoders, SHAP, LIME
Related Posts:
- AI Second Philosophy (Why process comes before AI)
- Intelligent CAD Integration with LLMs (Combining neural embeddings with enterprise search)
- Healthcare & Pharmaceutical Solutions (ML for credentialing and supply chain)
About: HSEC has been integrating machine learning and neural networks into enterprise systems for nearly two decades, with a focus on production reliability, explainability, and measurable business impact. Our “AI Second” philosophy ensures that ML enhances robust processes rather than replacing them.