Edge AI for R&D: Strategic Advantage Through On-Premise Intelligence
Introduction: The Coming Edge AI Revolution in R&D
Within the next few years, edge AI capabilities will reach a tipping point: Companies will be able to run sophisticated AI models entirely on-premise, powerful enough to deliver real business value without sending proprietary data to external cloud services.
This shift has profound strategic implications for R&D-intensive organizations:
The traditional trade-off:
- Option A: Send sensitive R&D data to cloud AI services (OpenAI, Google, AWS) → Get powerful AI capabilities, but lose data sovereignty and risk IP leakage
- Option B: Keep data on-premise → Maintain security and control, but miss out on AI capabilities
The emerging reality:
- Edge AI eliminates the trade-off: Run powerful AI models locally on enterprise hardware, combining security with capability
But here’s the critical insight: Edge AI alone isn’t the strategy—how you apply it is.
AI Second Philosophy: Where Edge AI Truly Belongs
Before diving into edge AI capabilities, we must understand where AI should—and shouldn’t—be applied.
Our AI Second Principle
AI Second = Business process and deterministic logic first, AI augmentation second (not first).

Why this matters for edge AI:
-
Don’t use AI where deterministic code works better
- Bad: AI model to calculate compound interest → Classical formula is 100% accurate, instant, explainable
- Good: AI model to predict when equipment will fail → No perfect formula exists, pattern recognition needed
-
Don’t use AI where human creativity is essential
- Bad: AI generates entire product design → Lacks strategic vision, brand understanding, user empathy
- Good: AI assists designer by exploring variations → Human sets direction, AI accelerates iteration
-
Do use AI for pattern recognition and augmentation
- Analyzing thousands of simulation results to find optimal parameters
- Detecting anomalies in test data that humans would miss
- Predicting material performance based on composition
Edge AI’s sweet spot in R&D: Augmenting human researchers and engineers with pattern recognition, prediction, and automation—while keeping sensitive IP on-premise.
Data Sovereignty: Why On-Premise Matters for R&D
The Intellectual Property Challenge
R&D organizations create enormous value through proprietary knowledge:
Automotive R&D example:
- Vehicle platform designs (5-10 years of competitive advantage)
- Simulation models for crash testing, aerodynamics, NVH
- Material formulations and supplier relationships
- Test data from prototype vehicles
- Engineering know-how and design trade-offs
Pharmaceutical R&D example:
- Drug compound designs and molecular structures
- Clinical trial data (patient privacy + competitive intelligence)
- Manufacturing processes and formulation secrets
- Research failures (what didn’t work—valuable competitive knowledge)
Aerospace R&D example:
- Aerodynamic designs and computational fluid dynamics (CFD) models
- Materials science research (composites, alloys)
- Control system algorithms
- Test flight data and performance envelopes
Challenge: To use cloud AI services (ChatGPT, Claude, Gemini), you typically must send your data to external servers.
Risks:
- Data exposure: Your proprietary designs/data leave your control
- Model contamination: Cloud providers may train on your data (even if anonymized, patterns leak)
- Regulatory compliance: GDPR, ITAR, export controls may prohibit cloud transfer
- Competitive intelligence: Competitors using same cloud service might infer your research directions
Edge AI as Data Sovereignty Solution
On-premise edge AI architecture:
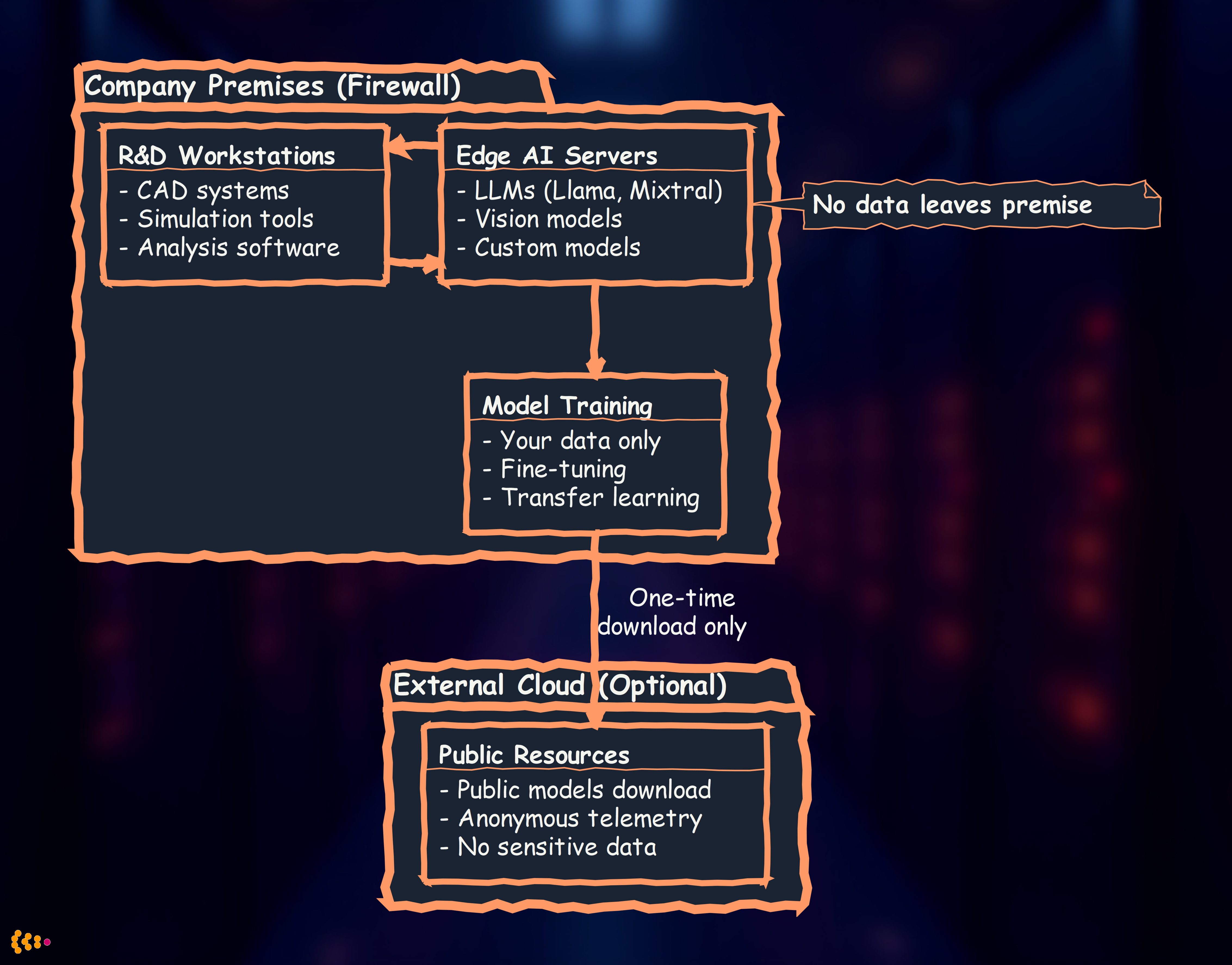
Benefits:
- Full data control: Sensitive designs, test data, trade secrets never leave your network
- Compliance: Satisfy ITAR, GDPR, corporate security policies
- Custom models: Fine-tune AI on your proprietary data without exposure
- Competitive advantage: Your AI learns from your unique data, competitors can’t replicate
Strategic Advantage: Custom AI Applications in R&D
Generic AI vs. Custom AI
Generic cloud AI (ChatGPT, Claude, Gemini):
- Trained on public internet data
- General-purpose capabilities
- Available to everyone (including competitors)
- No competitive advantage: Everyone has access to the same capabilities
Custom edge AI:
- Trained or fine-tuned on your proprietary data
- Domain-specific capabilities (your industry, your products)
- Available only to you
- Strategic differentiation: Your AI knows things competitors’ AI doesn’t
Real-World R&D Use Cases for Edge AI
Use Case 1: Engineering Simulation Analysis
Challenge: Automotive OEM runs 50,000+ crash test simulations per new vehicle platform. Engineers manually review results to identify optimal designs.
Classical approach: Engineers write rules (“if deceleration >60G, flag design”)
- Problem: Misses complex multi-variable patterns, brittle rules
Cloud AI approach: Send simulation data to cloud for analysis
- Problem: Exposing proprietary vehicle designs and safety performance data
Edge AI solution:

AI augmentation (AI Second principle):
- Deterministic: Physics calculations, safety thresholds → Classical code
- AI: Pattern recognition across 50,000 simulations → Edge AI model
- Human: Final design decisions, trade-off evaluation → Engineering team
Results:
- 80% reduction in manual review time (50,000 → 10,000 engineer-reviewed designs)
- 15% better designs identified (AI found patterns engineers missed)
- Zero IP exposure: All data stays on-premise
Use Case 2: Materials Research Acceleration
Challenge: Materials science team testing 1,000+ polymer formulations for new battery technology. Each physical test costs €500 and takes 2 weeks.
Classical approach: Systematic testing of all combinations
- Problem: 1,000 formulations × €500 × 2 weeks = €500K and 2,000 weeks (38 years sequential)
Cloud AI approach: Use ML to predict promising formulations, test only those
- Problem: Proprietary formulation data is competitive crown jewel
Edge AI solution:
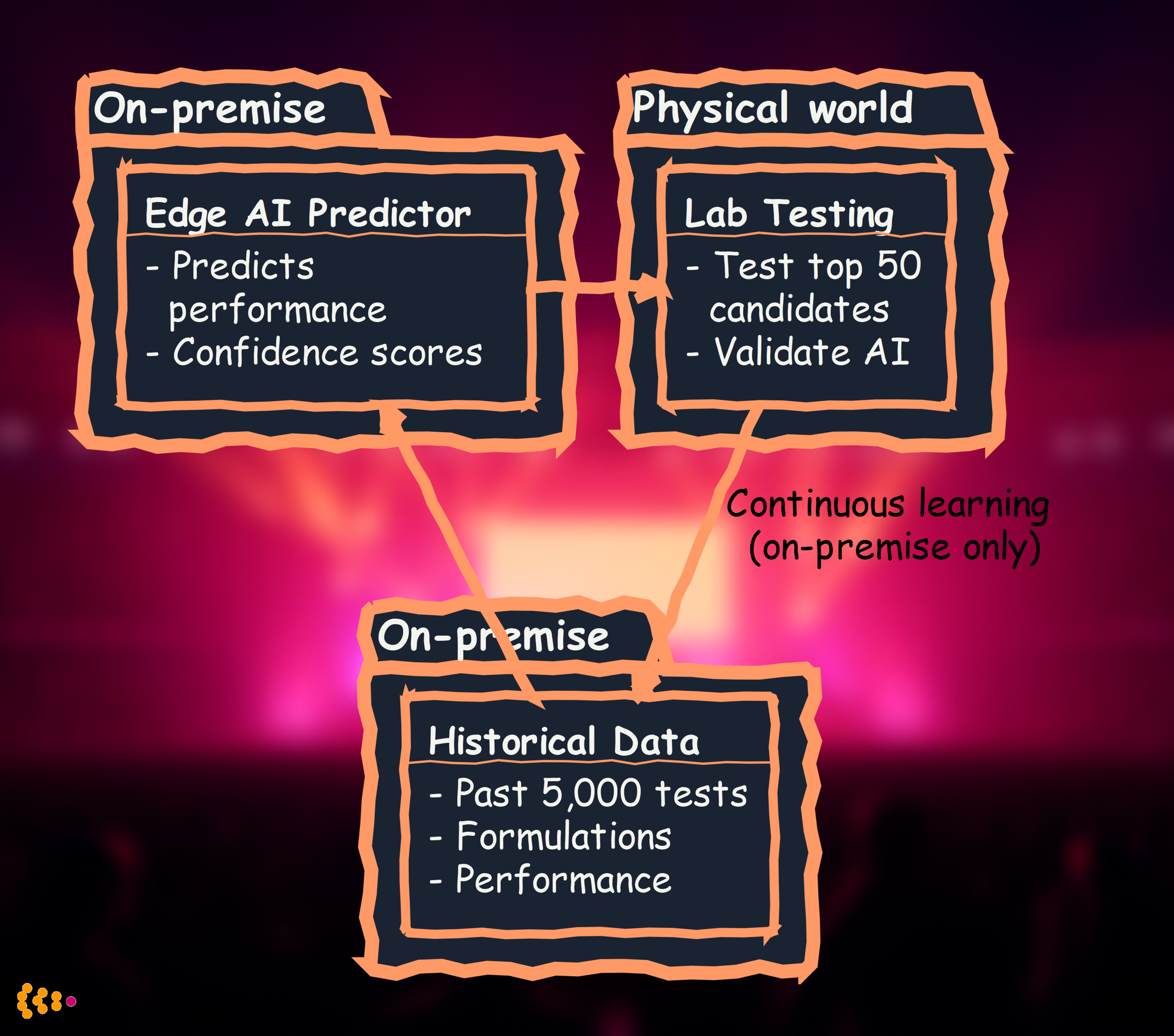
AI augmentation:
- Deterministic: Chemical compatibility rules, safety constraints → Classical code
- AI: Predict performance from formulation → Edge AI model (trained on your data)
- Human: Research strategy, interpret results, publish findings → Scientists
Results:
- 95% reduction in testing needed (1,000 → 50 formulations physically tested)
- 18 months faster to market (vs. systematic testing)
- Competitive moat: Your AI trained on your proprietary test data, competitors can’t replicate
- IP protection: Zero formulation data sent to external services
Use Case 3: Product Design Iteration with AI-Assisted CAD
Challenge: Industrial design team creates 200+ design variations for new consumer electronics product. Evaluating manufacturability, aesthetics, ergonomics manually takes weeks.
Classical approach: Designers manually check each design against manufacturing constraints
- Problem: Slow, inconsistent, misses subtle issues
Cloud AI approach: Use generative AI to create design variations
- Problem: Sending CAD files to cloud exposes product designs pre-launch (leak risk)
Edge AI solution:
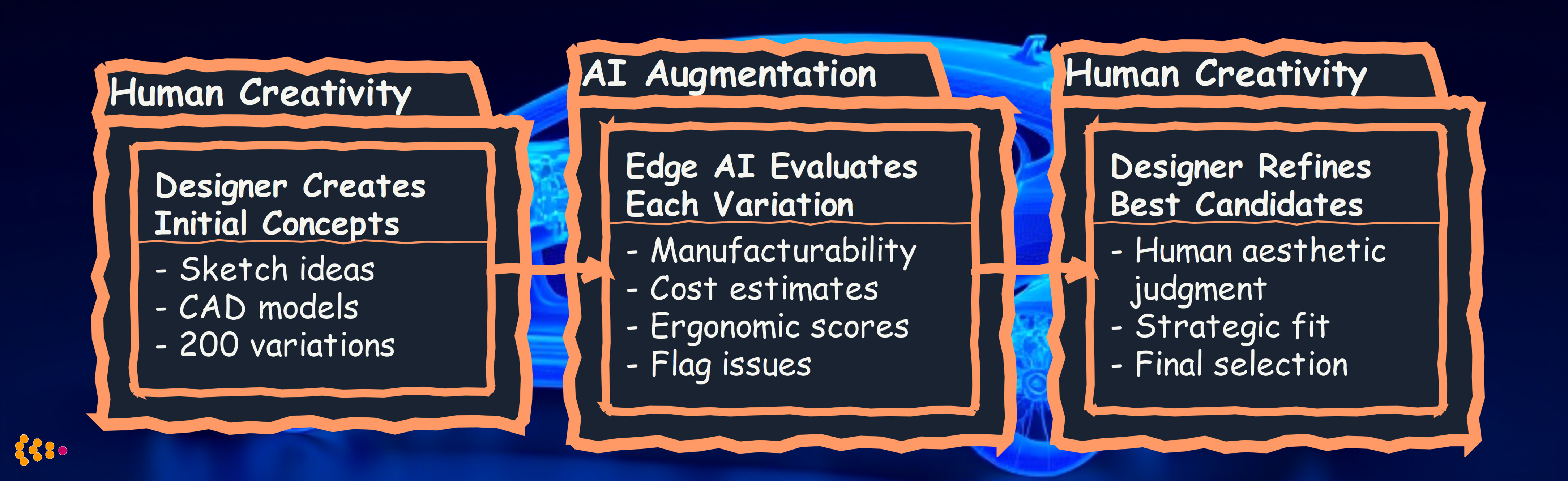
AI augmentation:
- Deterministic: Manufacturing constraints (min wall thickness, max overhang) → Classical rules
- AI: Aesthetic consistency with brand, ergonomic comfort prediction → Edge AI model
- Human: Creative vision, brand strategy, user experience → Designers
Results:
- 5x faster iteration cycles (weeks → days for design evaluation)
- Fewer late-stage manufacturing issues (AI catches problems earlier)
- Zero design leaks: All CAD data stays on-premise until product launch
- Brand consistency: AI trained on company’s design language (not generic)
Use Case 4: Test Data Anomaly Detection
Challenge: R&D testing generates terabytes of sensor data (prototype vehicles, lab tests, field trials). Engineers can’t manually review all data for anomalies.
Classical approach: Set threshold alerts (temperature >100°C, pressure <5 bar)
- Problem: Misses complex multi-sensor patterns, generates false positives
Cloud AI approach: Send sensor data to cloud for ML-based anomaly detection
- Problem: Test data reveals product performance characteristics (competitive intelligence)
Edge AI solution:

AI augmentation:
- Deterministic: Hard safety limits (never exceed X) → Classical alerts
- AI: Subtle pattern deviations, early warning signs → Edge AI anomaly detector
- Human: Root cause analysis, engineering judgment on severity → R&D team
Results:
- Early issue detection: 2-3 weeks earlier warning vs. threshold-based alerts
- 92% reduction in false positives (vs. simple threshold rules)
- Prevented critical failure: Detected bearing degradation 6 weeks before catastrophic failure in €2M prototype
- Data privacy: Sensitive test data never leaves test facility
The Technology: Edge AI Platforms for R&D
Hardware Requirements (2026-2028 Outlook)
Current state (2026):
- Entry-level: NVIDIA RTX 4090 (24GB VRAM) — Run 7B-13B parameter models
- Professional: NVIDIA A100/H100 (40-80GB VRAM) — Run 30B-70B parameter models
- Enterprise cluster: 4-8× H100s — Run 70B-180B parameter models on-premise
Near future (2027-2028 projection):
- Moore’s Law continues: Next-gen GPUs with 2-3x performance/$ improvement
- Model optimization: Quantization, pruning enable 70B models on consumer hardware
- Specialized AI chips: Edge AI accelerators (Google TPU, Apple Neural Engine equivalents for servers)
Cost trajectory:
- 2026: ~€10,000 for entry-level edge AI server (RTX 4090 workstation)
- 2028 projection: ~€5,000 for equivalent capability (or €10,000 for 3x capability)
Implication: On-premise AI becomes economically viable for mid-size R&D teams (not just tech giants).
Software Stack for Edge AI in R&D
Open-source foundation models (run on-premise):
-
Large Language Models (LLMs):
- Meta Llama 3 (8B, 70B, 405B variants) — General reasoning, code generation
- Mistral/Mixtral (7B, 8×7B, 8×22B) — European option, strong technical capabilities
- Qwen (7B-72B) — Multilingual, strong STEM performance
-
Vision Models:
- CLIP (OpenAI, open weights) — Image understanding and classification
- Segment Anything (Meta SAM) — Object segmentation in images
- Stable Diffusion (open source) — Image generation and modification
-
Domain-Specific Models:
- ESMFold (protein structure prediction) — Pharma/biotech R&D
- GNoME (materials discovery) — Materials science
- ChemBERTa (chemical property prediction) — Chemistry R&D
Fine-tuning frameworks:
# Example: Fine-tune Llama 3 on proprietary engineering data
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoRA, get_peft_model
# Load base model (on-premise)
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-70b")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3-70b")
# Apply LoRA for efficient fine-tuning
lora_config = LoRA(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)
# Train on your proprietary data (never leaves premise)
trainer.train(your_proprietary_dataset)
# Deploy for inference (on-premise)
inference_server.deploy(model)
Benefits of open-source models:
- Data sovereignty: Download once, run forever on-premise (no API calls to external services)
- Customization: Fine-tune on your proprietary data
- Cost control: No per-token pricing, unlimited usage
- Compliance: Satisfy security/regulatory requirements
Edge AI Deployment Patterns for R&D
Pattern 1: Departmental Edge AI Server
Setup: Single powerful server (8× NVIDIA H100) serving R&D department
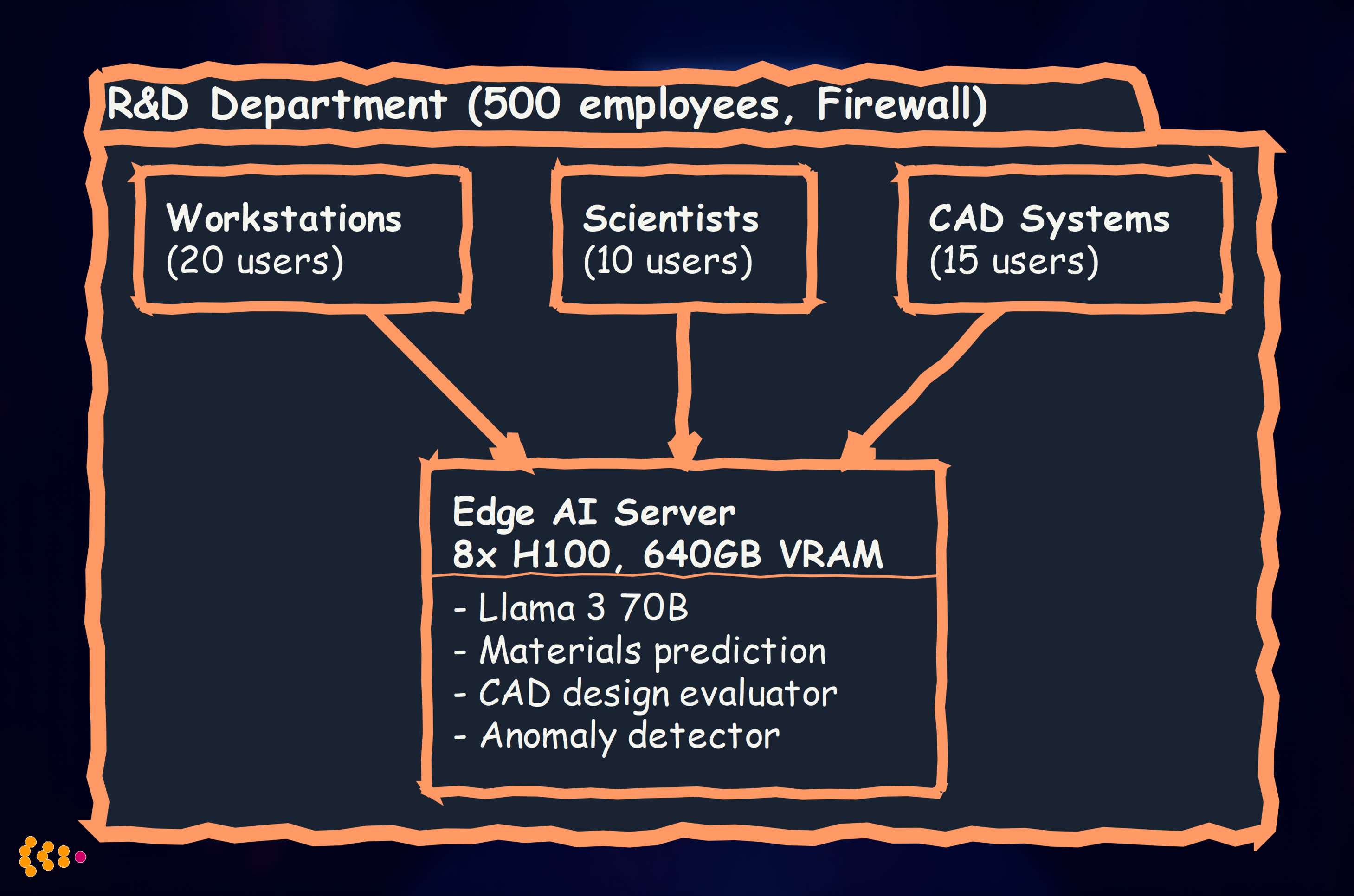
Cost: ~€200,000 (2026 pricing for 8× H100 server) ROI calculation:
- R&D team productivity increase: 20% (conservative)
- 45 engineers/scientists × €100K avg salary × 20% = €900K annual value
- Payback period: 3 months
Pattern 2: Hybrid Edge-Cloud (Tiered Sensitivity)
Setup: Non-sensitive tasks use cloud, sensitive tasks stay on-premise
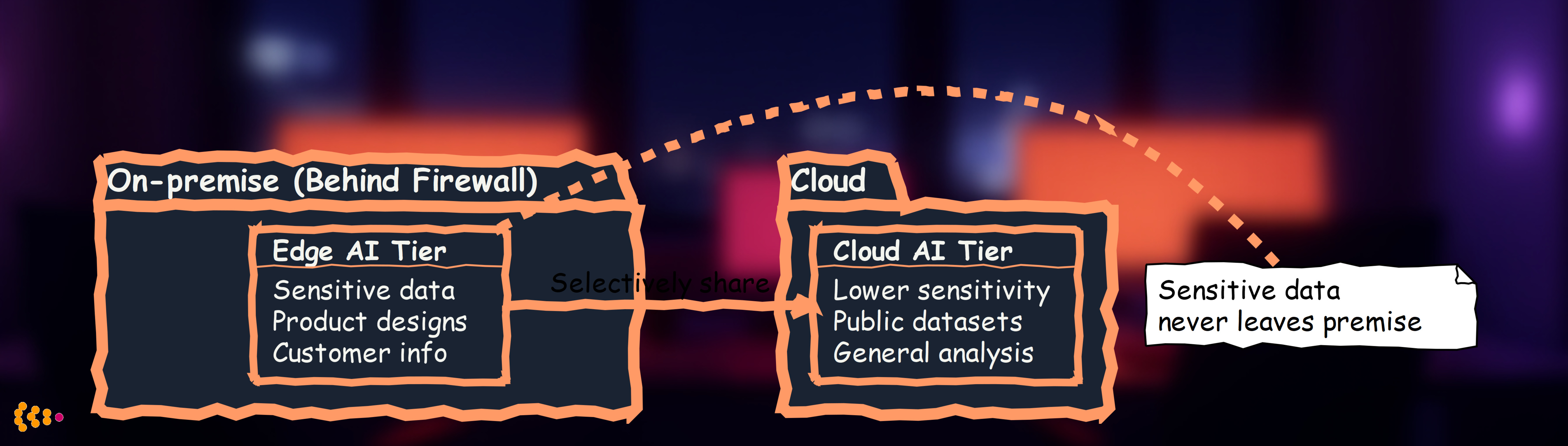
Decision criteria:
- On-premise edge AI: Any data classified as “confidential” or higher
- Cloud AI: Public information, already-published data, vendor collaboration
Pattern 3: Federated Learning Across R&D Sites
Setup: Multiple R&D locations (Germany, USA, Japan) each run edge AI, periodically synchronize models (without sharing raw data)
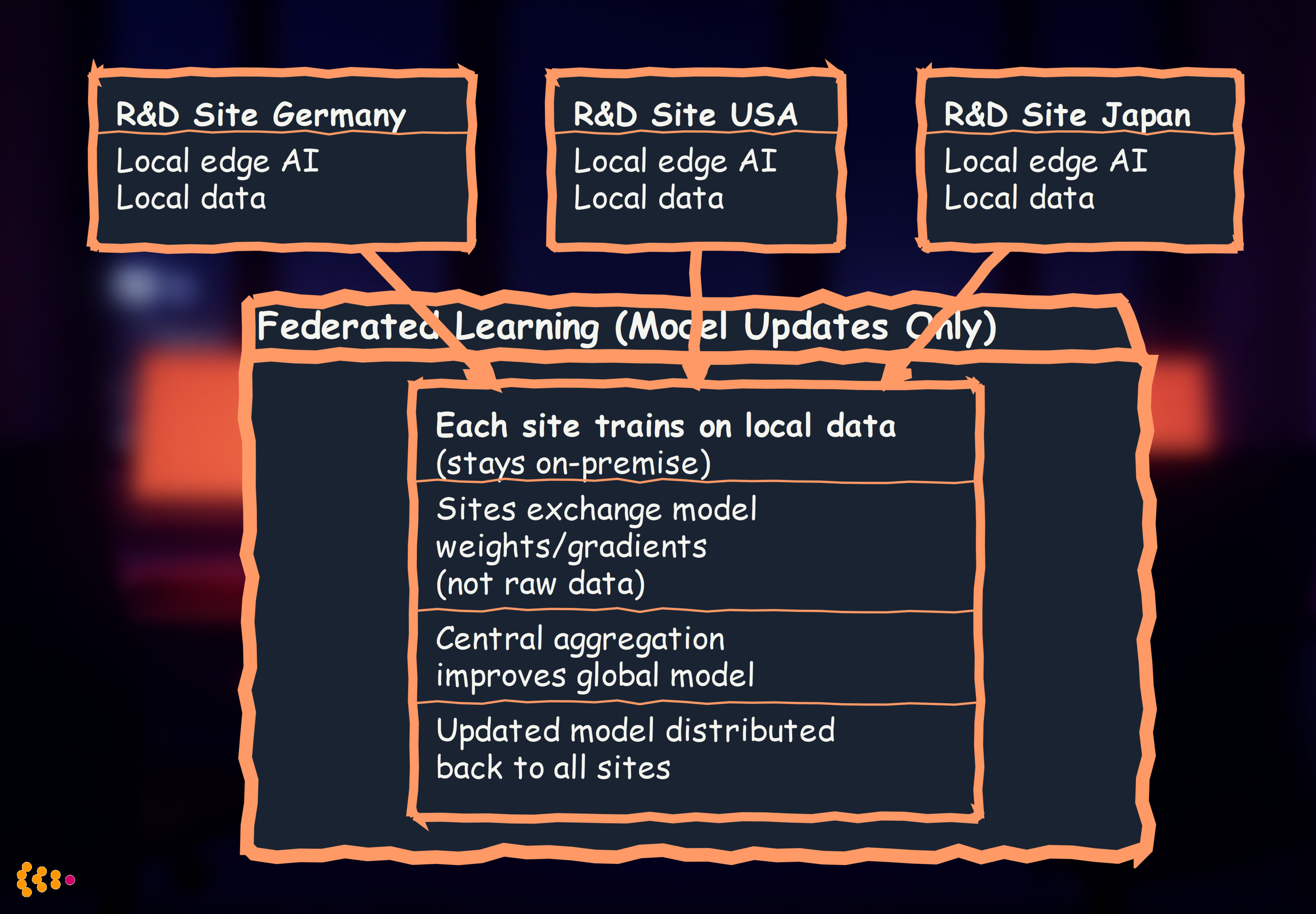
Benefits:
- Data sovereignty: German data stays in Germany (GDPR), US data in US (ITAR if applicable)
- Collective learning: All sites benefit from each other’s data without exposing it
- Regulatory compliance: No cross-border data transfer
Building Strategic Advantage with Custom Edge AI
The Competitive Moat
Generic AI (cloud services everyone uses):
- Commoditized capability
- No differentiation
- Competitors have equal access
Custom Edge AI (trained on your proprietary data):
- Unique to your organization
- Reflects your domain expertise
- Competitors cannot replicate (they lack your data)
Example: Automotive OEM Material Selection AI
Generic cloud AI:
Human: "What material should I use for this automotive part?"
Cloud AI: "Common choices are aluminum, steel, or carbon fiber.
Aluminum is lightweight, steel is strong, carbon fiber
is expensive but high-performance."
→ Generic advice anyone could get
Custom edge AI (trained on your 20 years of material performance data):
Human: "What material should I use for this automotive part?"
Custom AI: "Based on 847 similar parts in our history:
- Aluminum alloy 6061-T6 works well (15 parts, 99.2% field reliability)
- Avoid steel here (12 parts, 78% reliability due to corrosion in this location)
- Carbon fiber is overkill (cost +€45/part, no performance gain for this load case)
- Recommend: 6061-T6 with zinc coating (€12/part, 99.5% reliability projection)"
→ Specific, actionable advice based on YOUR proprietary data
Strategic value: Your AI knows things competitors’ AI doesn’t (your failure modes, your supplier performance, your cost structures).
How to Build Custom Edge AI for R&D
Step 1: Identify High-Value Use Cases (AI Second principle)
Ask: “Where is AI augmentation valuable, but not replacing deterministic logic or human creativity?”
Good candidates:
- ✅ Pattern recognition across thousands of test results
- ✅ Predicting outcomes based on historical data
- ✅ Anomaly detection in complex sensor data
- ✅ Accelerating design iteration with evaluative feedback
Poor candidates:
- ❌ Calculations that have exact formulas (use classical code)
- ❌ Creative strategic decisions (human judgment)
- ❌ Safety-critical deterministic controls (use provable algorithms)
Step 2: Collect and Curate Proprietary Training Data
Your competitive advantage comes from your unique data:
Example data assets for R&D:
- Historical test results (pass/fail, performance metrics)
- Design iterations (what was tried, what worked/didn’t work)
- Simulation results (input parameters → output performance)
- Failure analysis reports (root causes, fixes)
- Manufacturing feedback (designs that were hard/easy to produce)
Data preparation:
# Example: Prepare automotive crash test data for AI training
import pandas as pd
# Load 10 years of crash test simulations
crash_data = pd.read_parquet('crash_simulations_2014_2024.parquet')
# Feature engineering
crash_data['deceleration_rate'] = crash_data['delta_v'] / crash_data['duration']
crash_data['energy_absorption_ratio'] = crash_data['absorbed_energy'] / crash_data['impact_energy']
# Label creation (binary classification: safe vs. unsafe)
crash_data['safe'] = (crash_data['head_injury_criterion'] < 700) & \
(crash_data['chest_deceleration'] < 60)
# Train-test split (stratified by vehicle platform)
from sklearn.model_selection import train_test_split
train, test = train_test_split(crash_data, stratify=crash_data['platform'])
# Train edge AI model (on-premise)
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier()
model.fit(train[features], train['safe'])
# Save for on-premise deployment
import joblib
joblib.dump(model, '/edge_ai_server/models/crash_safety_predictor_v1.pkl')
Key: This model is trained on YOUR crash test data (competitors don’t have access).
Step 3: Fine-Tune Foundation Models on Your Data
For LLM-based applications, fine-tune open-source models:
Example: Engineering Q&A Assistant
from transformers import AutoModelForCausalLM, Trainer, TrainingArguments
# Load base Llama 3 70B model (downloaded once, runs on-premise forever)
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-70b")
# Prepare your proprietary Q&A dataset
# Example: 10,000 engineering questions from internal forums + expert answers
proprietary_qa_dataset = load_dataset('internal/engineering_qa_2014_2024')
# Fine-tune on YOUR data (stays on-premise)
training_args = TrainingArguments(
output_dir='/edge_ai_server/models/engineering_assistant',
num_train_epochs=3,
per_device_train_batch_size=4,
learning_rate=2e-5
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=proprietary_qa_dataset
)
trainer.train() # All training on-premise
# Deploy for inference
model.save_pretrained('/edge_ai_server/models/engineering_assistant_v1')
Result: LLM that understands YOUR company’s engineering terminology, YOUR product history, YOUR domain knowledge.
Step 4: Deploy and Monitor On-Premise
Deployment architecture:
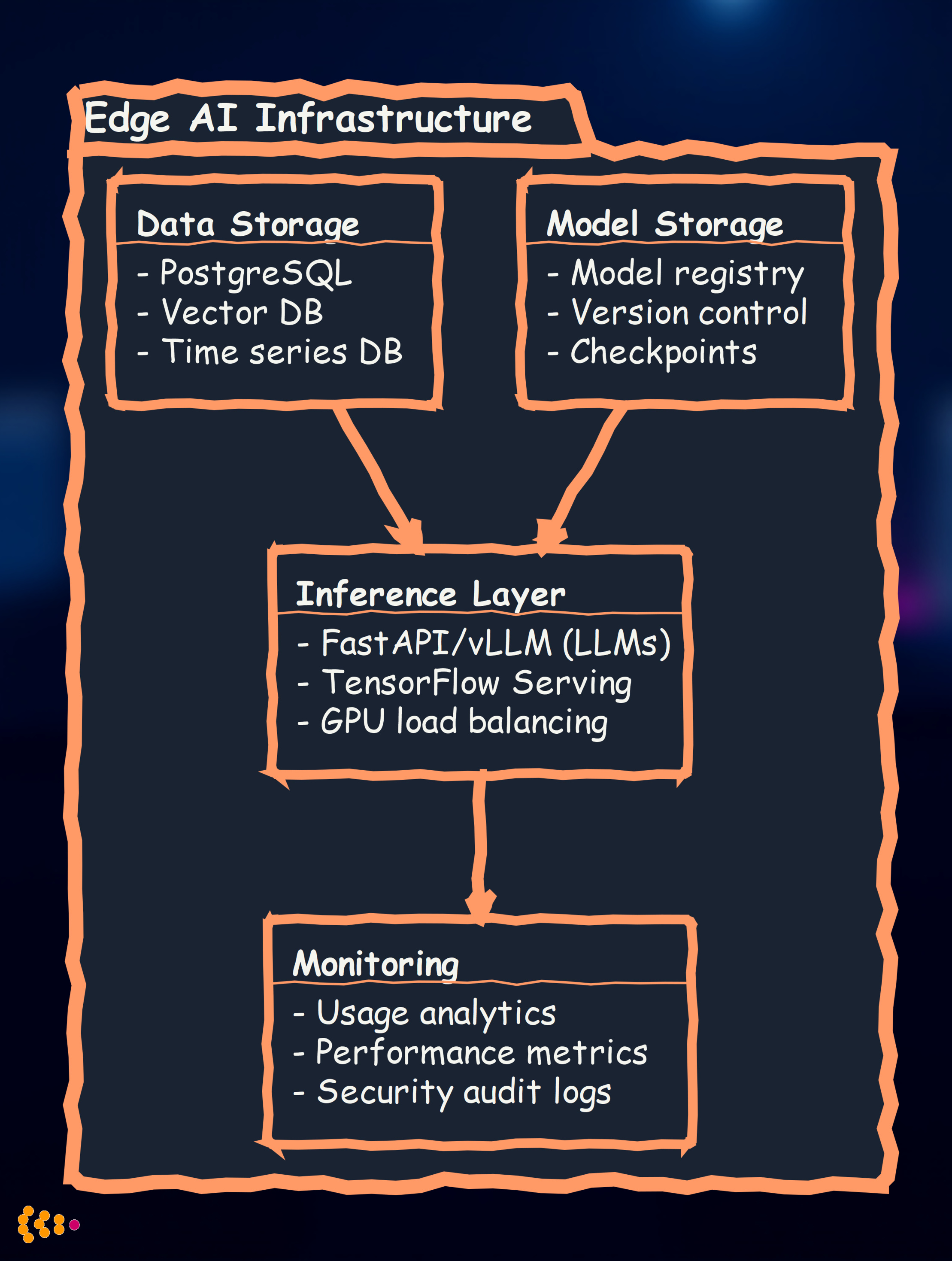
Continuous improvement:
- Collect user feedback on AI responses
- Retrain quarterly with new proprietary data
- A/B test model versions (v1 vs. v2) to measure improvement
Lessons Learned: Edge AI in R&D Environments
1. Start with Use Cases, Not Technology
Anti-pattern: “We need edge AI!” → Deploy infrastructure → Search for use cases
Best practice:
- Identify high-value R&D challenges (where is manual work slow/error-prone?)
- Evaluate if AI is appropriate (pattern recognition? not deterministic? not pure creativity?)
- Choose edge vs. cloud based on data sensitivity
- Deploy minimal viable solution, measure impact
- Scale what works
2. Respect the AI Second Principle
Don’t use AI where classical code works:
- ❌ Bad: AI model to calculate stress-strain curves → Use finite element analysis (FEA)
- ✅ Good: AI model to predict which designs will fail FEA → Pattern recognition across thousands of FEA results
Don’t use AI where human creativity is essential:
- ❌ Bad: AI generates entire research strategy → Lacks vision, context, strategic judgment
- ✅ Good: AI suggests research papers relevant to your current problem → Augments researcher’s literature review
Do use AI for augmentation:
- ✅ AI analyzes 10,000 simulation runs, flags top 100 for human review → 100x speedup
- ✅ AI predicts material performance, human validates with physical test → Faster iteration
3. Data Quality Determines AI Quality
Edge AI is only as good as your proprietary training data:
- High-quality data: Accurate labels, comprehensive coverage, minimal bias → Excellent AI performance
- Low-quality data: Mislabeled examples, gaps in coverage, systematic errors → Poor AI performance
Investment priority:
- 70% effort: Data collection, curation, labeling
- 20% effort: Model selection and training
- 10% effort: Deployment infrastructure
Example: Automotive supplier spent 6 months collecting high-quality failure mode data (1,200 labeled examples). Resulting AI model achieved 94% accuracy. Competitor rushed with 2 weeks of poor data collection (200 examples, inconsistent labels) → 67% accuracy → Abandoned project.
4. Security is Paramount
Edge AI doesn’t automatically mean secure:
- Network segmentation: Isolate edge AI servers on separate VLAN from general corporate network
- Access controls: Role-based access (who can query AI? who can retrain models?)
- Audit logging: Track all AI queries and model updates (regulatory compliance, insider threat detection)
- Model encryption: Encrypt model weights at rest (prevents IP theft if server compromised)
- Input validation: Prevent adversarial attacks (malicious inputs designed to confuse AI)
Best practice: Treat edge AI servers like crown jewel assets (same security as your most sensitive R&D data).
5. Plan for Model Evolution
Models degrade over time:
- R&D processes change (new materials, new regulations)
- Data distribution shifts (new product platforms, new test methods)
- Competitor AI improves (your edge erodes if you stand still)
Continuous improvement strategy:

Example: Automotive materials AI retrained every 6 months with new test data (200+ new formulations/year). Model accuracy increased from 88% (v1.0) → 94% (v2.0 after 2 years).
The Future: Edge AI Capabilities in 2027-2030
Projected Advances
Hardware (2027-2028):
- 10x more powerful edge AI servers at same cost (vs. 2026)
- Consumer-grade GPUs run 70B models (today requires enterprise hardware)
- Specialized AI chips (inference-optimized, 5-10x more efficient than GPUs)
Software (2027-2030):
- Multimodal models standard: Text + image + 3D CAD + sensor data in single model
- Agentic AI: Edge AI autonomously runs experiments, analyzes results, proposes next steps (human approves)
- Improved reasoning: Models approach human expert level on narrow technical domains
Implications for R&D:
- 2026: Edge AI assists humans (pattern recognition, prediction)
- 2028: Edge AI as junior researcher (runs routine analyses, flags anomalies, suggests experiments)
- 2030: Edge AI as domain expert peer (engages in technical discussions, proposes novel solutions, BUT human retains final creative/strategic decisions)
AI Second principle still applies: Deterministic → classical code, Creative strategy → humans, Pattern recognition/augmentation → AI.
Conclusion: Edge AI as Strategic R&D Asset
Within the next few years, edge AI will enable organizations to:
- Leverage powerful AI capabilities (approaching cloud AI performance) entirely on-premise
- Protect intellectual property (sensitive R&D data never leaves your control)
- Build competitive moats through custom AI trained on proprietary data
- Accelerate R&D cycles (faster simulation analysis, materials discovery, design iteration)
- Maintain compliance (GDPR, ITAR, export controls satisfied by on-premise deployment)
But technology alone isn’t the strategy—how you apply it is.
Our AI Second philosophy guides effective use:
- Deterministic tasks: Classical programming (100% reliable, explainable)
- Pattern recognition and augmentation: AI (edge or cloud, based on sensitivity)
- Creative and strategic work: Human expertise (irreplaceable)
The winning R&D organizations of 2030:
- Deploy edge AI where it augments (not replaces) human researchers
- Build custom AI on their unique proprietary data (competitive differentiation)
- Respect the boundaries (deterministic logic → code, creativity → humans, patterns → AI)
- Continuously evolve their AI capabilities (quarterly retraining, A/B testing, feedback loops)
The losers:
- Send all R&D data to generic cloud AI (lose IP sovereignty, gain no competitive edge)
- OR refuse AI entirely (fall behind competitors who augment effectively)
- OR misapply AI to deterministic/creative tasks (frustration, poor results)
Edge AI isn’t the future—it’s arriving now. The question is: Will you use it strategically?
Related Articles:
- AI Second Philosophy: Business Process First, AI Augmentation Second — Our foundational principle for responsible AI deployment
- Machine Learning and Neural Networks in Enterprise Applications — Technical deep dive into ML model development and deployment
- Analytics & Data Science: Multi-Platform Expertise — Building data infrastructure to support AI initiatives
Ready to explore edge AI for your R&D organization? Contact us to discuss your strategic AI roadmap.
Typical Industrial Edge Deployment
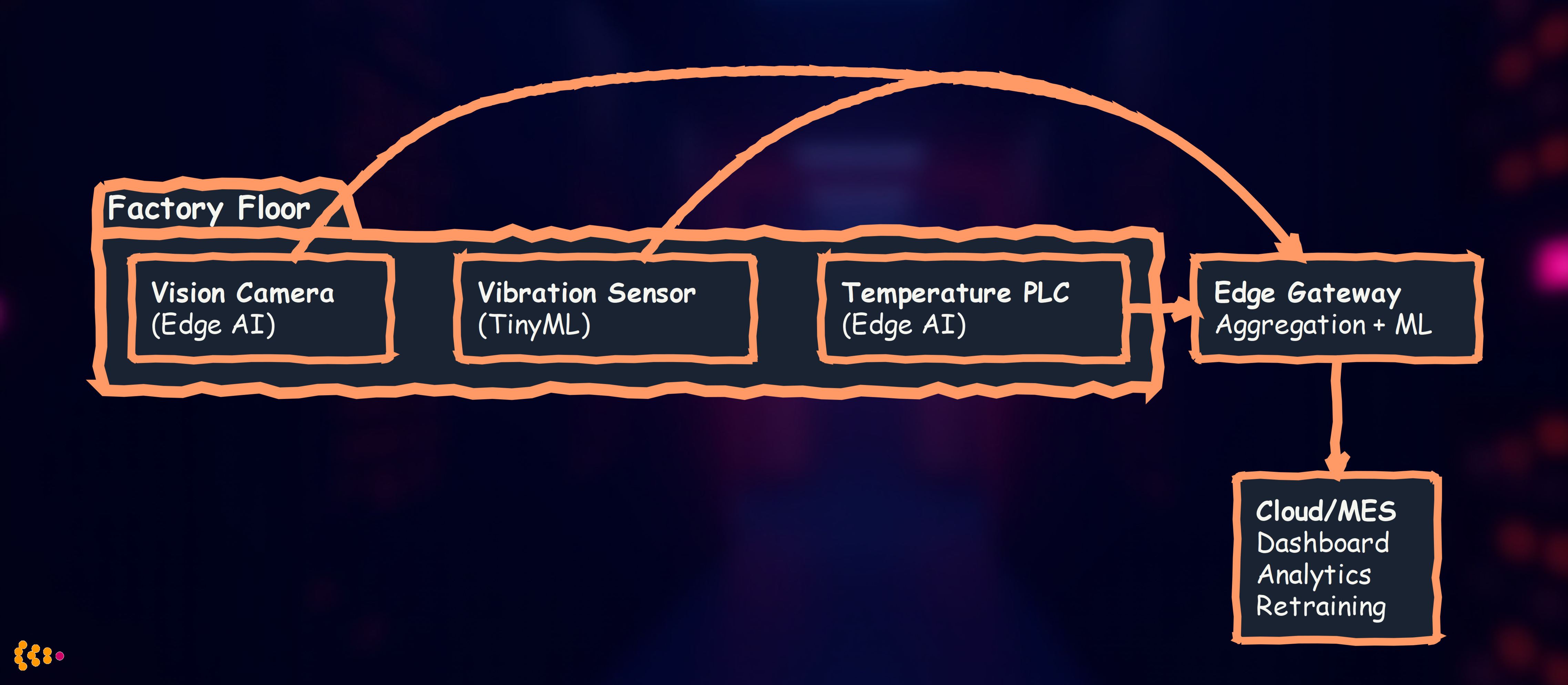
Three-Tier Architecture:
- Device Edge: ML on sensors, cameras, PLCs (µs to ms latency)
- Edge Gateway: Aggregate data, run heavier models (ms to seconds)
- Cloud: Long-term storage, model training, dashboards (seconds to minutes)
Use Case 1: Predictive Maintenance on Industrial PLCs
Challenge
Manufacturing plant has 200+ machines. Each has a Programmable Logic Controller (PLC) monitoring temperature, vibration, pressure. Traditional approach: Send all data to cloud for analysis.
Problems:
- 200 PLCs × 10 sensors × 1 KB/sec = 2 MB/sec continuous data stream
- Cloud egress costs: ~$500/month just for network
- Latency: 200ms cloud round-trip—too slow to prevent damage
Edge AI Solution
Deploy TinyML model directly on PLCs:

Technical Implementation:
Model: Lightweight autoencoder for anomaly detection
# TinyML model for PLC (quantized to 8-bit integers)
import tensorflow as tf
def create_tiny_autoencoder():
model = tf.keras.Sequential([
tf.keras.layers.Dense(16, activation='relu', input_shape=(10,)),
tf.keras.layers.Dense(8, activation='relu'), # Bottleneck
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(10, activation='linear') # Reconstruction
])
return model
# Train in cloud
model = create_tiny_autoencoder()
model.fit(normal_sensor_data, normal_sensor_data, epochs=50)
# Quantize for edge deployment
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
# Deploy to PLC (model size: ~5 KB)
Deployment:
- Hardware: Siemens S7-1500 PLC with TIA Portal
- Runtime: TensorFlow Lite Micro (C++ library for embedded systems)
- Inference time: < 10ms per sensor reading
- Power: No additional power—runs on PLC’s existing CPU
Results:
- 95% reduction in cloud data transfer (only alerts sent, not raw data)
- <10ms latency for anomaly detection (vs. 200ms cloud)
- $400/month savings on cloud egress costs
- Zero downtime during network outages (autonomous operation)
Use Case 2: Quality Inspection with Edge Vision AI
Challenge
Automotive parts manufacturer inspects 10,000+ parts/day for defects (cracks, scratches, dimensional errors). Manual inspection is slow, inconsistent, and expensive.
Edge AI Solution
Deploy computer vision models on edge cameras:
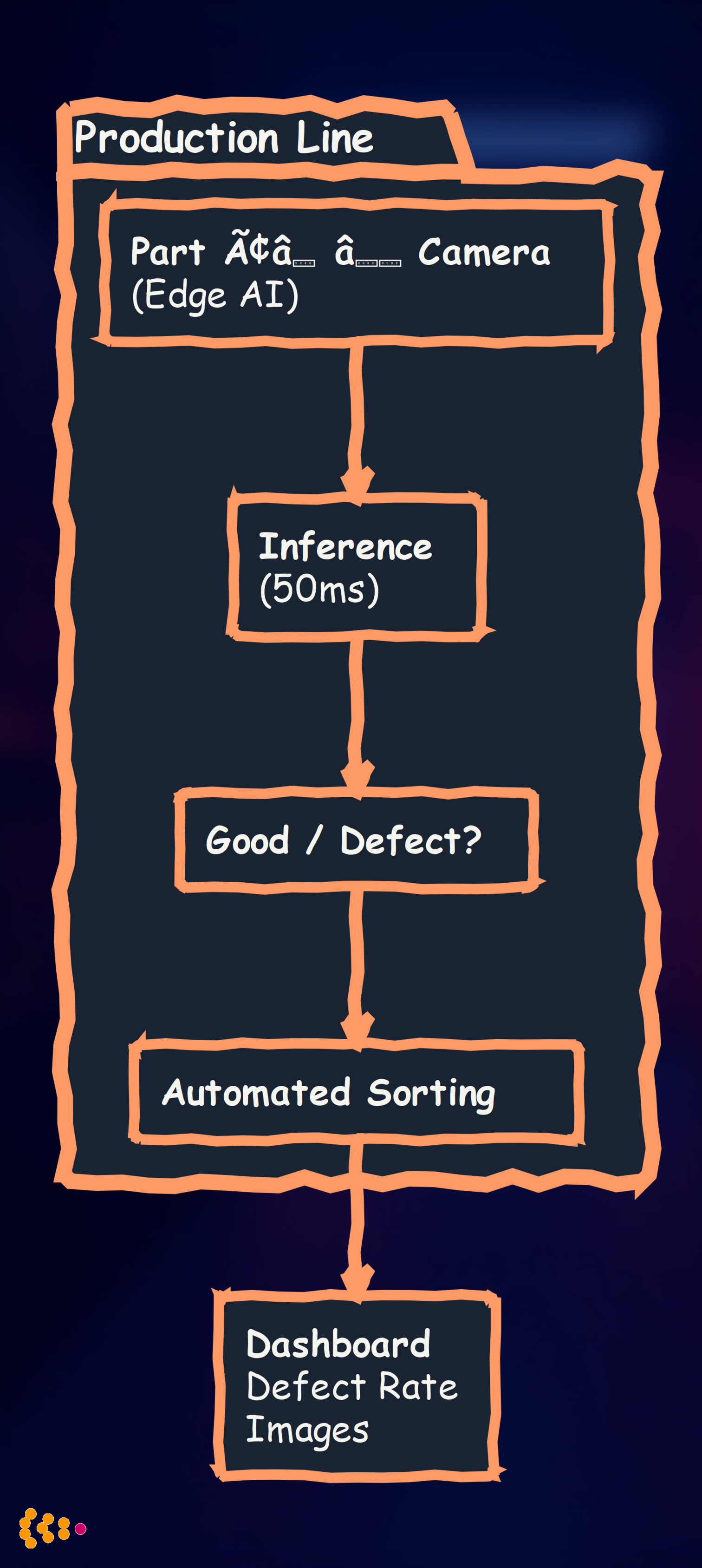
Technical Stack:
Hardware: NVIDIA Jetson Nano (edge GPU, $99) Model: MobileNetV3 + custom defect detection head Framework: PyTorch → TensorRT (optimized for Jetson)
Model Architecture:
import torch
import torchvision.models as models
class DefectDetector(torch.nn.Module):
def __init__(self, num_defect_classes=5):
super().__init__()
# Pre-trained MobileNetV3 (efficient for edge)
self.backbone = models.mobilenet_v3_small(pretrained=True)
# Replace classifier for defect detection
self.backbone.classifier = torch.nn.Sequential(
torch.nn.Linear(576, 128),
torch.nn.Hardswish(),
torch.nn.Dropout(0.2),
torch.nn.Linear(128, num_defect_classes)
)
def forward(self, x):
return self.backbone(x)
# Optimize for Jetson with TensorRT
import torch2trt
model_trt = torch2trt.torch2trt(model, [example_input], fp16_mode=True)
Deployment:
- Camera: Industrial camera (1920×1080, 60 FPS)
- Inference: 50ms per image (20 FPS processing)
- Accuracy: 98.5% defect detection (vs. 92% manual inspection)
- Power: 10W (Jetson Nano)
Results:
- 100% inspection coverage (vs. 5% sampling with manual inspection)
- 60% cost reduction (fewer inspectors needed)
- 2x throughput (no bottleneck waiting for manual inspection)
- Defect image logging for quality analysis and model retraining
Use Case 3: Real-Time Process Control with Edge AI
Challenge
Chemical manufacturing plant adjusts reactor temperature, pressure, and feed rates based on sensor readings. Traditional PID controllers use fixed parameters—not optimal for varying conditions.
Edge AI Solution
Deploy reinforcement learning agent on edge controller:
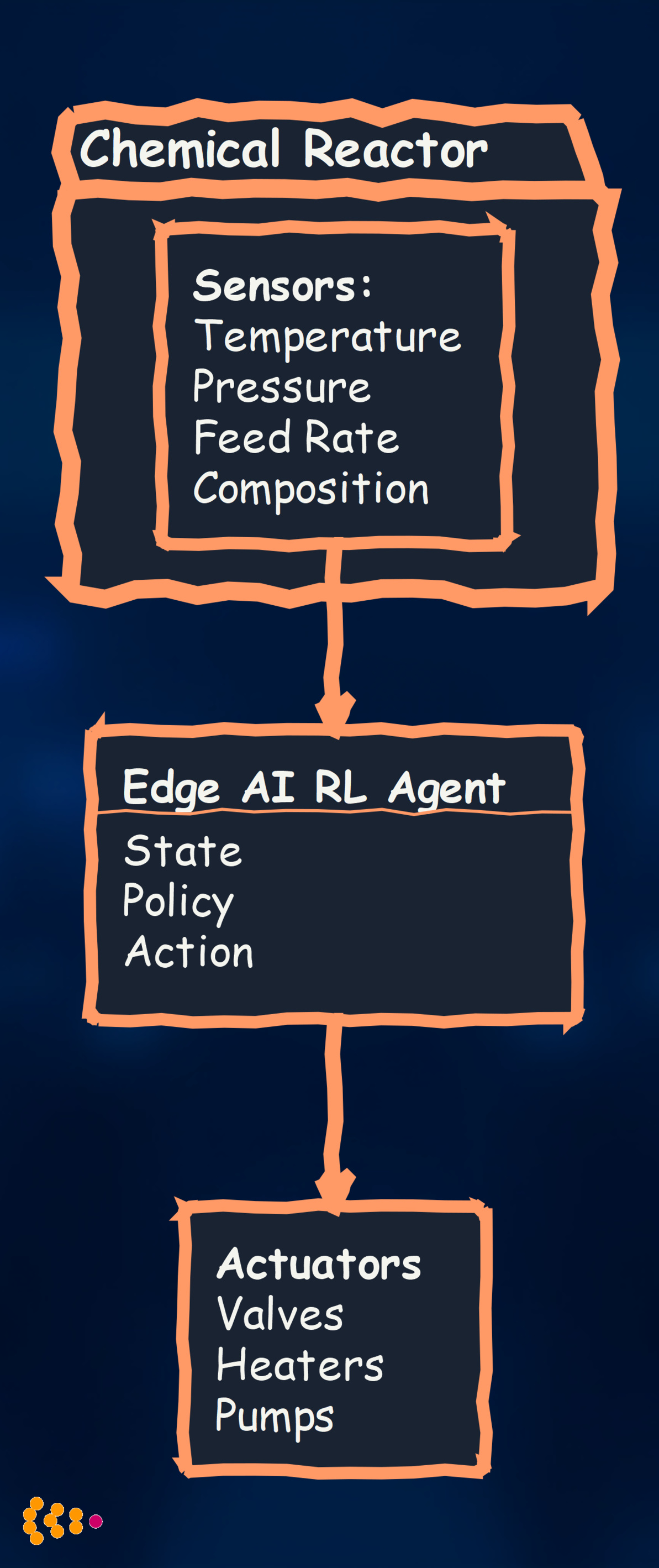
Technical Approach:
Model: Deep Q-Network (DQN) for process control Training: Simulated environment (digital twin) + fine-tuning on real reactor Deployment: Edge controller with GPU (NVIDIA Jetson Xavier)
Simplified RL Agent:
import torch
import torch.nn as nn
class ProcessControlAgent(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, action_dim) # Q-values for each action
)
def forward(self, state):
return self.fc(state)
def select_action(self, state):
with torch.no_grad():
q_values = self.forward(state)
return torch.argmax(q_values).item()
# Deployed on edge with <100ms inference time
Results:
- 12% energy savings (optimized heating/cooling cycles)
- 8% yield improvement (better process control)
- <100ms control loop (vs. 5-10 seconds with cloud)
- Autonomous operation during network outages
TinyML: Machine Learning on Microcontrollers
What is TinyML?
TinyML = ML models running on microcontrollers (µCs) with:
- < 1 MB RAM
- < 1 MB flash storage
- < 1mW power (battery-operated)
Example Devices:
- Arduino Nano 33 BLE Sense
- ESP32 (WiFi/Bluetooth microcontroller)
- Arm Cortex-M4/M7 processors
TinyML for Vibration Monitoring
Use Case: Wireless vibration sensors on 500+ motors
Traditional Approach:
- WiFi sensors send raw vibration data to gateway
- Battery life: 2-3 months (constant WiFi transmission)
TinyML Approach:
- Run anomaly detection model on sensor
- Only transmit alerts (not raw data)
- Battery life: 2-3 years
Model Optimization:

Quantization Example:
import tensorflow as tf
# Train full model
model = train_model(vibration_data)
# Quantize to 8-bit integers
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.int8]
tflite_model = converter.convert()
# Model size: 100 KB → 10 KB (10x reduction)
# Inference time: 5ms → 0.8ms (6x faster)
# Accuracy: 95.2% → 94.8% (minimal degradation)
Results:
- 10-20x battery life improvement
- 99% reduction in network traffic
- <1ms inference time on microcontroller
- Scalable: 500+ sensors with no cloud bottleneck
Edge AI Technology Stack
Hardware Platforms
Ultra-Low Power (TinyML):
- Arduino Nano 33 BLE Sense: $33, Cortex-M4, sensors included
- ESP32: $10, WiFi/Bluetooth, 520 KB RAM
- STM32 Nucleo: $15-30, Cortex-M7, industrial-grade
Edge GPU (Vision, Heavy ML):
- NVIDIA Jetson Nano: $99, 128-core GPU, 4 GB RAM
- NVIDIA Jetson Xavier NX: $399, 384-core GPU, 8 GB RAM
- Google Coral Dev Board: $150, Edge TPU, fast inference
Industrial Controllers:
- Siemens S7-1500: PLC with TIA Portal, 2 MB RAM
- Beckhoff CX5000: Industrial PC, multi-core Intel Atom
- Raspberry Pi 4 (Industrial): $75, quad-core ARM, 8 GB RAM
Software Frameworks
Model Training:
- TensorFlow: Full ML framework, cloud training
- PyTorch: Research-friendly, flexible
- Edge Impulse: End-to-end TinyML platform (training + deployment)
Edge Inference:
- TensorFlow Lite: Quantized models, runs on mobile/embedded
- TensorFlow Lite Micro: C++ library for microcontrollers (TinyML)
- TensorRT: NVIDIA GPU optimization (10x faster inference on Jetson)
- ONNX Runtime: Cross-platform, supports multiple frameworks
Edge Orchestration:
- Azure IoT Edge: Microsoft’s edge runtime
- AWS Greengrass: Amazon’s edge compute platform
- KubeEdge: Kubernetes for edge computing
Edge AI Best Practices
1. Model Optimization is Critical
Techniques:
- Quantization: 32-bit float → 8-bit int (4x smaller, faster)
- Pruning: Remove low-importance neurons (50-90% reduction)
- Knowledge Distillation: Train small model to mimic large model
- Model Architecture: Use efficient designs (MobileNet, EfficientNet)
Optimization Workflow:

2. Edge-Cloud Hybrid Architecture
Don’t choose edge OR cloud—use BOTH:
| Task | Where | Why |
|---|---|---|
| Real-time inference | Edge | <10ms latency |
| Model training | Cloud | GPU clusters, large datasets |
| Model updates | Cloud → Edge | OTA (over-the-air) deployment |
| Long-term analytics | Cloud | Data warehousing, dashboards |
| Anomaly alerts | Edge → Cloud | Minimal data, urgent action |
3. Continuous Model Updates
Edge models degrade over time:
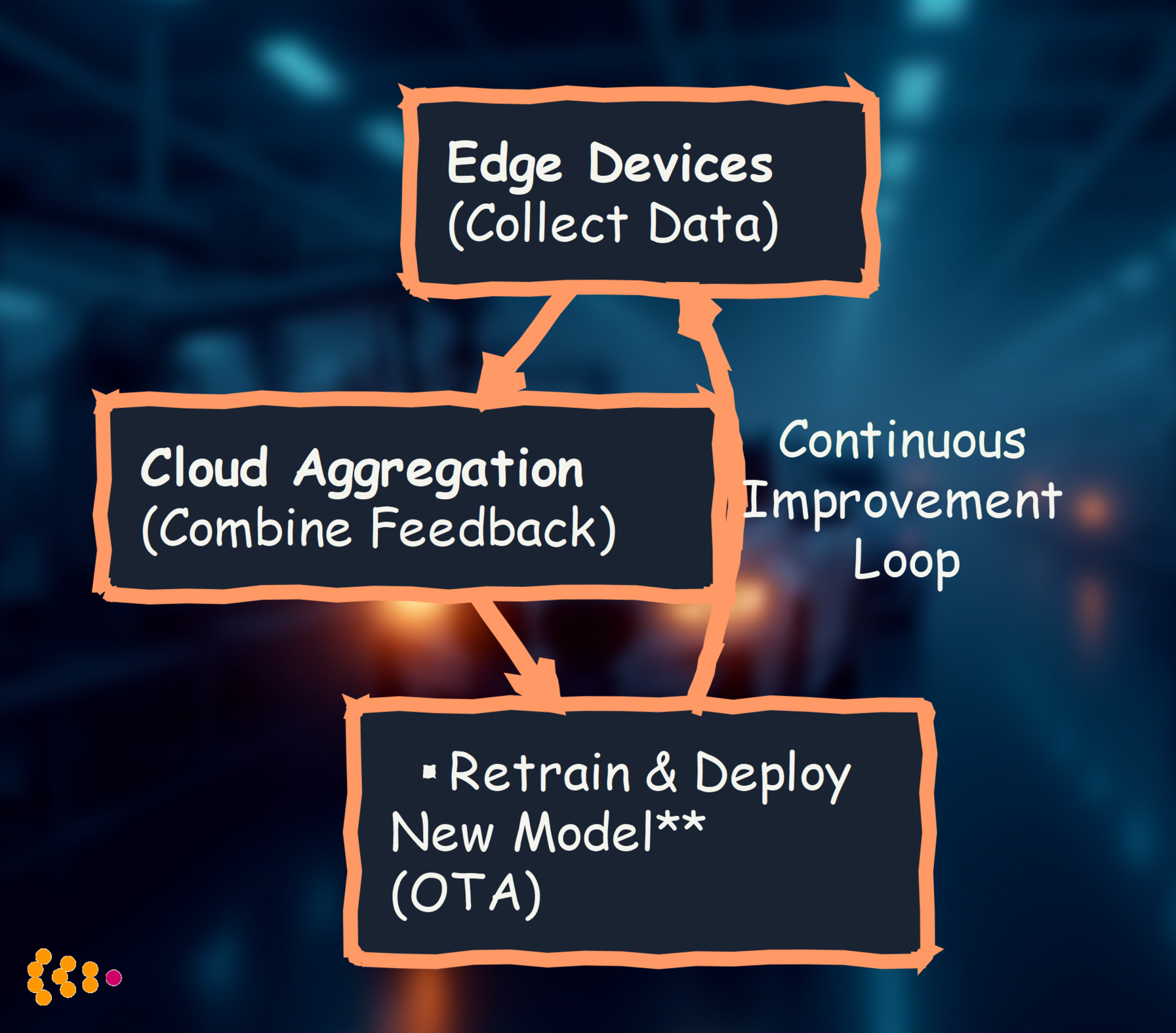
Our Approach:
- Weekly/Monthly retraining: Capture changing conditions
- A/B testing: Deploy new model to 10% of devices first
- Rollback capability: Revert if accuracy degrades
- OTA updates: Push new models without physical access
4. Security is Non-Negotiable
Edge Threats:
- Physical access: Devices on factory floor can be tampered with
- Network attacks: Edge devices are internet-exposed
- Model extraction: Adversary can steal proprietary models
Mitigations:
- Encrypted storage: Models encrypted at rest
- Secure boot: Prevent unauthorized firmware
- Model obfuscation: Make reverse-engineering harder
- Anomaly detection: Detect if device is compromised
Challenges and Limitations
1. Model Accuracy Trade-offs
Problem: Quantization/pruning reduce accuracy
Mitigation:
- Target < 2% accuracy degradation
- Use larger models on edge gateways (more compute available)
- Ensemble methods: Combine multiple small models
2. Hardware Constraints
Problem: Limited RAM, storage, compute on edge devices
Solution:
- Streaming inference: Process data in chunks, not all at once
- Model caching: Load/unload models as needed
- Hardware acceleration: Use edge TPUs, GPUs when available
3. Connectivity is Unreliable
Problem: Industrial environments have spotty network coverage
Design Principle:
- Autonomous operation: Edge devices must work offline
- Local buffering: Queue data/alerts when network is down
- Graceful degradation: Degrade to simpler logic if ML fails
The Future of Edge AI in Manufacturing
1. Federated Learning at the Edge
Train models across multiple factories without centralizing data:
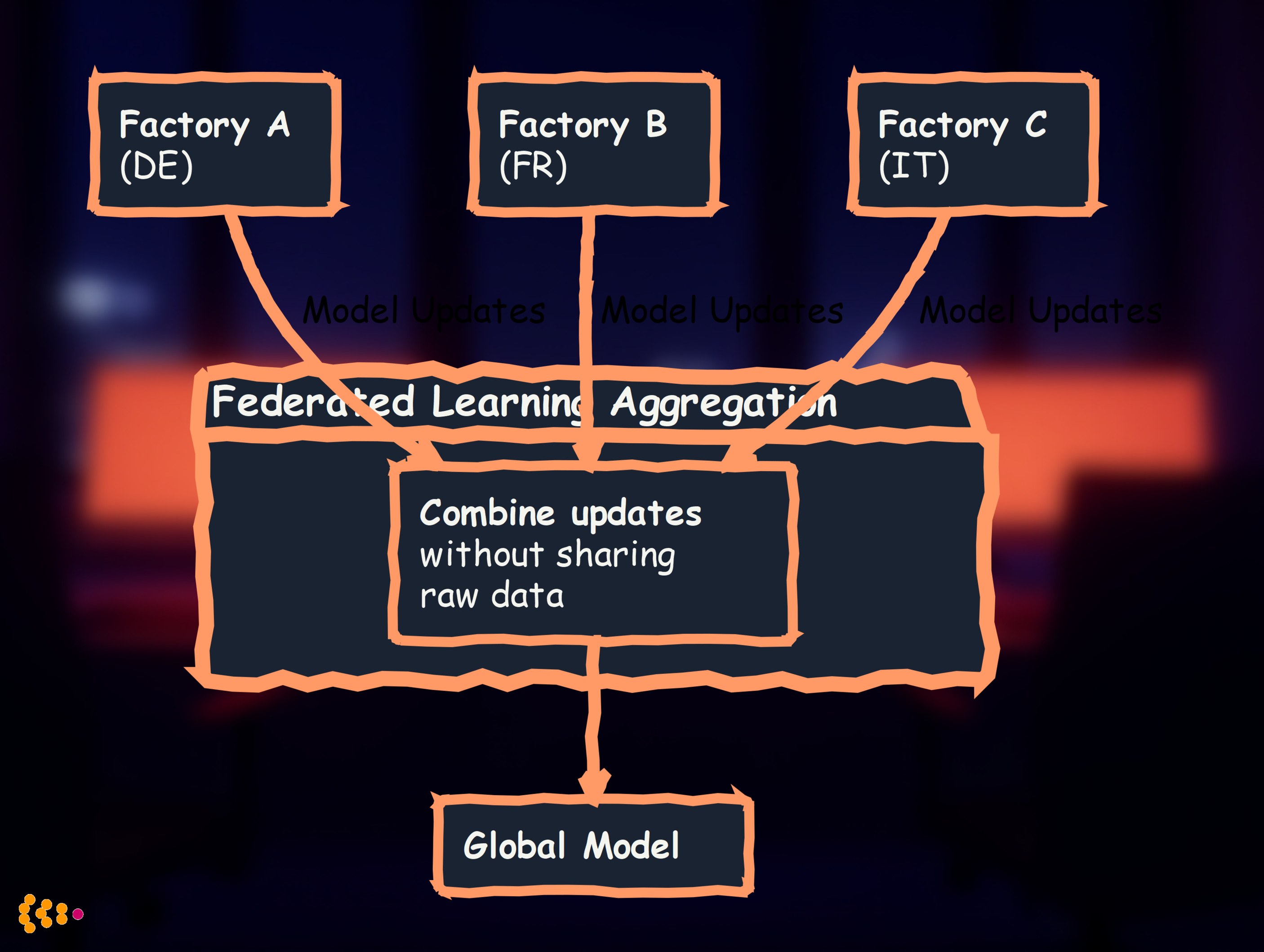
Benefits:
- Privacy: Data never leaves factory
- Compliance: GDPR-friendly (no data transfer)
- Collective intelligence: Learn from all factories
2. Neuromorphic Computing
Spiking Neural Networks (SNNs) on specialized hardware:
- 10-100x more energy efficient than traditional neural networks
- Event-driven: Only compute when sensor values change
- Hardware: Intel Loihi, IBM TrueNorth
3. Edge AI + Digital Twins
Simulate factory in real-time, predict future states:

Use Cases:
- What-if analysis: Test process changes in simulation first
- Predictive optimization: Optimize tomorrow’s production based on today’s data
- Anomaly detection: Compare real vs. simulated—flag deviations
Lessons Learned: Edge AI in Production
What Works
✅ Start with high-ROI use cases: Predictive maintenance, quality inspection
✅ Edge-cloud hybrid: Use both, optimize for each
✅ Model optimization: Quantization, pruning are essential
✅ Continuous updates: Retrain models regularly
✅ Autonomous operation: Edge must work offline
What Doesn’t Work
❌ Edge-only architectures: Need cloud for training, analytics
❌ Complex models on microcontrollers: TinyML requires simplicity
❌ Ignoring power constraints: Battery life is critical for wireless sensors
❌ No security: Physical access enables attacks
❌ Manual deployment: OTA updates are mandatory at scale
Conclusion
Edge AI transforms industrial manufacturing from reactive (analyze after the fact) to proactive (detect and prevent in real-time):
- <10ms latency: Real-time control, quality inspection
- 99% data reduction: Only insights to cloud, not raw data
- Autonomous operation: No cloud dependency for critical decisions
- Privacy & compliance: Data stays on-premise
- Cost savings: Reduce cloud compute, network egress fees
The future factory is intelligent at the edge—and we’re building it today.
Technologies Used: TensorFlow Lite, TensorFlow Lite Micro, PyTorch, TensorRT, NVIDIA Jetson, Arduino, ESP32, Siemens S7-1500, Edge Impulse, ONNX Runtime, KubeEdge
Hardware Platforms: NVIDIA Jetson Nano/Xavier, Arduino Nano 33 BLE Sense, ESP32, Raspberry Pi 4, Siemens PLCs, Beckhoff Industrial PC
Related Posts:
- Machine Learning and Neural Networks (Training models for edge deployment)
- Modern Data Architecture (Edge data pipelines with Kafka)
- AI Second Philosophy (When edge AI makes sense)
About: HSEC deploys Edge AI and TinyML solutions for manufacturing, enabling real-time intelligence on industrial IoT devices. Our expertise spans model optimization, edge-cloud hybrid architectures, and production-grade edge deployments.